
<연재주제> R 기반의 데이터 시각화
<이번 연재 제목>R 프로그래밍 맛보기
<필자> 전희원 | 넥스알에서 데이터 사이언티스트로 일하고 있다.
<연재순서>
2회: R 프로그래밍 맛보기
3회: R로 데이터 다루기(data munging with R) (data.table, plyr, sqldf 패키지 비교·이용)
4회: ggplot2를 이용한 R 시각화
5회: Inkscape를 활용한 그래프 후처리
R은 데이터를 다루는 언어다. 데이터 획득과 조작(managing), 모델링, 시각화 등은 데이터 분석을 위한 큰 줄기에 해당하는 업무들이다. R은 분석 업무를 구석구석 최고로 다뤄줄 수 있는 툴과 같은 존재이자 통합 개발 환경(IDE)으로 볼 수 있다. 그 환경을 이해하려면 R 언어의 문법을 알 필요가 있다. 사실 R은 주변의 많은 프로그래밍 언어에서 영향을 받았다. 특히 Lisp라는 함수형 언어에서 영향을 받았는데, 이 때문에 많은 R 초보자들이 배움에 어려움을 겪고 있다. 하지만 이 덕분에 데이터 분석 시 복잡하고 이해하기 힘든 코드를 사용할 필요가 사라졌다.
필자가 R을 배우려고 했을 때, 일반적인 C++, 자바, 파이썬 같은 언어를 배울 때와 같은 자세로 임했다. 자랑은 아니지만 필자는 ‘1년에 하나의 새로운 프로그래밍 언어를 배운다’는 누군가의 지침을 충실히 따르고 있던 시점에 R을 접했다. 당시 필자가 가장 나중에 배운 언어는 Erlang이었다. Erlang도 함수형 언어다. 하기야 절차형 언어, 함수형 언어 모두에 경험이 있었으나 R을 배우는 데는 다른 큰 장벽이 버티고 있었다. 그건 바로 R 매뉴얼 곳곳에 숨어 있던 통계용어와 통계 개념이었다. 하지만 다행스럽게도 통계 용어를 배제하고 R 언어를 이해하는 건 어렵지 않았다. 여기서는 바로 그 접근 방법, 즉 통계 용어를 제외하고 R 언어와 친숙해질 수 있는 방법으로 접근하겠다.
인터렉티브 분석(interactive analysis)과 R
하둡 같은 분산 컴퓨팅 환경이 없을 때, 메인프레임 같은 대용량 컴퓨터에서 데이터 분석 비용은 매우 비쌌다. 때문에 마음 놓고 분석해볼 수 있는 여건이 아니었다. 따라서 컴퓨팅 환경과 분석 파라미터를 신중하게 선택·입력해야 했고, 그 결과 파일도 수백 페이지에 이르렀다. 이런 결과 파일에서 원하는 내용을 선별하고 나머지는 버렸다. 대부분의 통계 함수나 패키지들은 이런 대형 컴퓨터 환경일 때 개발됐고, 현재까지 그런 분석 결과를 보여주는 방식을 따르기도 한다.
하지만 개인용 컴퓨팅 환경이 일반화되기 시작하면서 예전처럼 한번에 설정하고 엄청난 양의 분석 결과를 얻는 그런 과정에서 벗어나기 시작한다. 다양한 데이터 입력, 변환, 무응답 대체(data imputation), 데이터 추가 및 삭제, 시각화, 모델링 과정 모두를 인터랙티브하게 수행하면서 분석가 자신이 갖고 있던 데이터에 대한 질문들에 대한 답을 완전히 얻을 수 있는 방법이 일반화됐다.
인터랙티브하게 분석한다는 것은 분석툴의 유연성을 기반으로 한다. 분석 시 사용한 코드는 다른 분석에서 재사용할 수 있어야 하며, 몇 번이고 유사한 분석을 큰 노력 없이 반복적으로 수행 가능해야 한다. 게다가 분석 데이터의 다양성 때문에 통계량으로 데이터를 이해하는 것 이상으로 시각화로 데이터를 이해하는 방법이 보편화됐다. ‘백 번 듣는 것보다 한 번 보는 게 낫다’는 말처럼, 나열된 수치보다 보기 쉽게 시각화한 결과가 훨씬 빠르고 확실한 상황 판단이 가능하기 때문이다.
이런 인터렉티브한 분석을 수행하기 위해 가장 적합한 환경 중 하나가 R이다. R은 수많은 소스에서 데이터를 가져올 수 있고, 최신의 다양한 알고리즘을 적용 가능하며, 언어적으로 재활용성을 중시해 CRAN(Comprehensive R Archive Network)이라는 패키지 배포 시스템을 갖고 있다. 게다가 분석가들이 가장 많이 사용하는 그래픽 라이브러리들을 포함하고 있다.
R을 설치하자
R은 http://r-project.org에서 내려받을 수 있다. R 자체뿐만 아니라 패키지라는 라이브러리와 같은 파일덩어리들은 CRAN이라는 곳에서 관리한다. Perl언어의 다운로딩 가능 리소스가 CPAN(Comprehensive Perl Archive Network)에서 일괄 관리되는 것과 같다. 따라서 R을 설치하기 위해서는 첫 페이지 왼쪽 메뉴에서 CRAN링크를 클릭한다. 이어서 ‘Korea’ 항목으로 이동해 http://cran.nexr.com을 선택하면, 각 운영체제별로 컴파일된 바이너리 또는 소스를 다운 받을 수 있다. 국내 통계 자료로 보자면 R 사용자의 90% 이상이 윈도우 운영체제를 사용하고 있으므로 앞으로 예제는 윈도우 기반으로 소개한다.
계속해서 ‘Download R for Windows’를 클릭해 나타나는 창에서 ‘base’를 선택해 R 바이너리를 내려 받는다. 사실 http://cran.nexr.com은 필자가 관리하고 있고, 넥스알에서 후원하고 있는 서버 리소스다. 하루에 두 번 메인 서버와 싱크하기 때문에 대부분의 경우 가장 최신의 파일을 담고 있다.
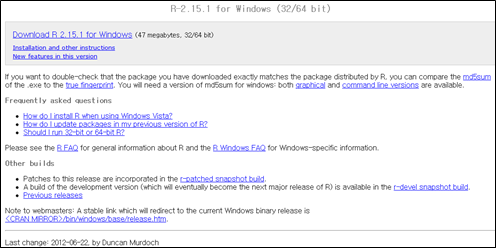
<그림1> 2012.7.10. 윈도우용 R 다운로드 페이지
많은 사용자가 64비트운영체제(OS)를 사용하는데, 이 바이너리를 설치할 때 x64 바이너리만 선택해 설치하기 바란다. 사실 64비트 OS에서는 x64바이너리가 가장 최적으로 작동하기 때문이다. 특히 운영체제에서 4GB이상의 메모리를 사용한다면 반드시 x64바이너리를 사용해야 한다. 물론 x86 바이너리를 함께 설치해도 작동에는 문제될 게 없지만, 사용하지 않을 바이너리까지 설치하면 시스템이 복잡해지고 공간낭비까지 불러온다. 설치과정에서는 ’32-bit Files를’ 체크 해제하면 x64 바이너리만 설치된다. 물론 32비트 OS를 사용한다면 그 역으로 접근하면 된다.
소스코드를 통해 직접 빌드해 보는 것도 R이 어떻게 동작하는지 이해할 수 있는 좋은 방법이지만, 그 과정이 간단하지 않고 본 연재의 주제와 직결되지 않아 여기서는 생략한다. 하지만 호기심 많은 독자라면직접 한번 시도해 보기 바란다.
RStudio를 이용하자
물론 처음부터 R 기본 쉘을 사용하는 것도 나쁘지 않지만, RStudio(http://www.rstudio.org/)를 사용하면 가장 최적의 R사용 환경을 유지할 수 있기 때문에 정말 편하다. RStudio는 그 자체만으로도 많은 기능을 포함하고 있어서 이곳에서 전체를 소개하기는 쉽지 않다. 일단 필자가 아는 RStudio의 장점은 다음과 같다.
– 에디터, 콘솔, 명령어 히스토리, 시각화, 파일탐색 등을 한 화면에서 보여준다.
– 프로젝트의 관점으로 파일 관리를 해준다. 물론 소스코드 관리 시스템과 연계할 수 있다.
– 문법 강조, 자동 코드 완성, 자동 들여쓰기 등 최적의 편집기를 갖고 있다.
– 빌트인 데이터 뷰어 내장, 플로팅 히스토리, R help 결합, Sweave, knitr 통합
– R Markdown 내장으로 문서와 코드를 결합할 수 있게 하고, 재현성 있는 분석을 가능하게 함
– 리눅스, 맥, 윈도우 등 멀티 플랫폼 지원
<그림 2>RStudio 화면
RStudio는 무엇보다 현재로서 가장 인기 있는 IDE(Integrated Development Environment)다. 게다가 클라이언트/서버 환경으로 설정해두면 풍부한 서버 리소스를 원격에서 활용할 수 있다. 특히 웹 브라우저 자체가 편집기가 되어 세션이 죽어도 최신의 작업 히스토리와 환경을 간직하고 있어 브라우저만 있으면 어느 곳에서든지 자신이 작업한 환경을 그대로 사용할 수 있다. 필자는 회사의 128GB 메모리 서버에 RStudio를 설치해두고 리소스가 풍부하지 않은 데스크톱에서 원격으로 접속해 사용하는데 정말 최고의 작업 환경이다.
R 퀵투어
R은 인터프리트 언어다. 콘솔에서 한줄의 명령어를 넣고 엔터를 치면 한 줄씩 실행되는 형태로 작업하게 된다.
할당 연산자는 ‘<-‘가 수행하는 형태다. 대부분의 언어에서 ‘=’를 사용하는 것과 대조적이지만 사실 ‘=’를 사용할 수도 있으나 표준에서는 이를 권장하지는 않는다. 따라서 예제에서는 ‘<-‘를 사용하도록 하겠다.
R을 설치할 때 함께 설치되는 base 패키지에는 1,100여 개의 함수가 존재한다. 그런 함수 호출은 다음과 같은 형식으로 수행된다.
|
returns<- function_name(arg1, arg2, …) |
대표적인 산술 연산자는 다음과 같다.
|
+ – * / ^ … |
R 환경에서 데이터는 기본적으로 vector, data.frame, matrix, list, factor 같은 형태로 존재한다.
일단 벡터(vector)는 아래와 같은 형태를 띤다.
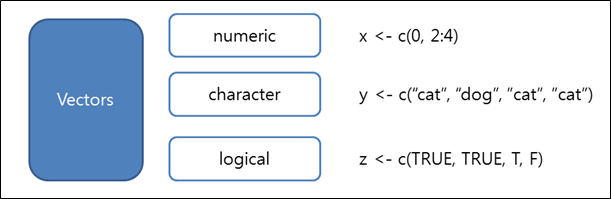
<그림 3> 벡터(vector) 자료형
|
>x<- c(0, 2:4) >class(x) [1] “numeric” >x2<- as.logical(x) >class(x2) [1] “logical” >x2 [1] FALSE TRUETRUETRUE >x3<- as.numeric(x2) >x3 [1] 0 1 11 > |
c()는 벡터(vector)로 만들어주는 역할을 하며, class 명령어는 객체의 타입을 알려주는 함수다. as.~류의 함수는 입력 받은 데이터형을 ~로 변환해주는 역할을 한다.
R에서는 함수에 넘겨지는 변수는 벡터화(vectorized)된 연산을 수행할 수 있게 한다. 따라서 아래와 같은 명령어가 예상한 대로 수행되는데, 다른 절차형 언어에서는 이런 결과를 얻으려면 for문을 활용해야 한다. 이런 식의 벡터화 지원은 데이터를 다룰 때 많은 코드를 줄여주고, 코드가 복잡해지는 것을 막아준다. 물론 코드를 읽는 사람 입장에서는 이해하기 쉬운 것은 당연하다. 그리고 R에서는 이런식의 연산이 for문을 사용하는 연산보다 훨씬 빠르게 동작한다.
|
>length(x) [1] 4 >x/2 [1] 0.0 1.0 1.5 2.0 > |
좀 더 자세한 예는 다음과 같다.
|
①>c(1,2,3,4,5,6) + c(6,5,4,3,2,1) [1] 7 7 7 7 7 7 ②>c(1,2,3,4,5,6) * 2 [1] 2 4 6 8 10 12 ③>c(1,2,3,4,5,6) * c(2,3) [1] 2 6 6 12 10 18 ④>c(1,2,3,4,5,6) * c(2,3,4) [1] 2 6 12 8 15 24 ⑤>c(1,2,3,4,5,6) * c(2,3,4,5) [1] 2 6 12 20 10 18 경고 메시지가 손실되었습니다 In c(1, 2, 3, 4, 5, 6) * c(2, 3, 4, 5) : 긴 개체의 길이가 더 짧은 개체의 길이의 배수가 되어 있지 않습니다 |
위에서 ①~② 예는 왜 저런 연산이 나오는지 독자들이 쉽게 예상할 수 있을 것이다. 하지만 ③~⑤의 예는 처음 접하는 독자에게는 쉽지 않을 수 있다. 그 이유는 연산 대상이 되는 긴 벡터의 길이가 곱해지는 작은 길이 벡터 길이의 배수일 경우에만 성공적인 연산이 수행된다. 따라서 ④에서는 성공했지만, ⑤에서 메시지가 손실됐다는 경고와 함께 ‘배수가 되어 있지 않다’는 안내 문구가 출력된다. 이는 데이터 연산의 유연성을 담보해 주기 위한 R언어의 특징이다.
나머지 대표적인 데이터 자료형에 대해 설명하면 다음과 같다.
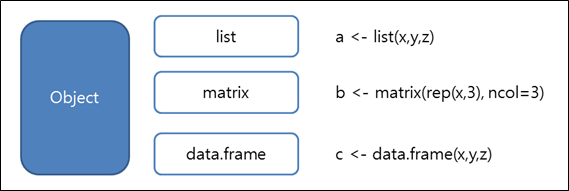
<그림 4> list, matrix, data.frame 자료형
a,b,c 객체의 출력 결과는 다음과 같다. 이때 a 메시지를 출력하기 위해서는 <그림 3>, <그림 4>의 코드를 수행한 뒤 가능하다.
|
>a [[1]] [1] 0 2 3 4
[[2]] [1] “cat” “dog” “cat” “cat”
[[3]] [1] TRUE TRUETRUE FALSE
>b [,1] [,2] [,3] [1,] 0 00 [2,] 2 22 [3,] 3 33 [4,] 4 44 >c x y z 1 0 cat TRUE 2 2 dog TRUE 3 3 cat TRUE 4 4 cat FALSE >class(a) [1] “list” >class(b) [1] “matrix” >class(c) [1] “data.frame” |
사실 x,y,z 변수는 서로 다른 데이터를 담고 있었다. 벡터는 한 가지 형만 담을 수 있다. 예를 들어 숫자형과 논리 자료형을 하나의 벡터에 담을 수 없지만, list에서는 x,y,z를 모두 담을 수 있다. matrix 자료형도 역시 벡터와 마찬가지로 한 가지 데이터형만 담을 수 있다. 반면 RDBMS의 테이블과 유사한 형태인 data.frame의 경우 모든 자료형을 담을 수 있다. 이런 관계를 테이블로 쉽게 표현하면 <표 1>과 같다.
<표 1> R의 자료형 구분
|
선형 |
직사각형 |
|
|
동질적 |
vector |
matrix |
|
이질적 |
list |
data.frame |
<표 1>에서 행은 담을 수 있는 데이터의 동질성 유무를 의미하고, 열은 데이터 구조 자체의 형태를 의미한다.
실제 대부분의 실무에서는 RDBMS의 테이블과 가장 유사한 성격을 가진 data.frame 객체를 가장 많이 쓴다. as.data.frame 함수로 matrix형에서 data.frame으로 변환할 수 있다.
데이터 자료형의 내부 데이터를 접근하는 방법은 R에서 매우 다양하다.
data.frame을 갖고 예를 들어보면 다음과 같다.
|
> class(df) [1] “data.frame” > df x y z 1 0 cat TRUE 2 2 dog TRUE 3 3 cat TRUE 4 4 cat FALSE > df$x [1] 0 2 3 4 > df[,1] [1] 0 2 3 4 > df$x == df[,1] [1] TRUE TRUE TRUE TRUE > df[1,] x y z 1 0 cat TRUE > df[1,]$x [1] 0 > df[1,]$z [1] TRUE > df[df$z,] ……………………① x y z 1 0 cat TRUE 2 2 dog TRUE 3 3 cat TRUE > df[c(1:3),] x y z 1 0 cat TRUE 2 2 dog TRUE 3 3 cat TRUE > df[c(1,2),] x y z 1 0 cat TRUE 2 2 dog TRUE > df[,c(1,3)] x z 1 0 TRUE 2 2 TRUE 3 3 TRUE 4 4 FALSE > df$k <- !df$z ……………………② > df x y z k 1 0 cat TRUE FALSE 2 2 dog TRUE FALSE 3 3 cat TRUE FALSE 4 4 cat FALSE TRUE |
위 표에서 df 데이터 객체는 data.frame이며, data.frame에 대한 다양한 연산 가능성을 보여준다. 대부분 인덱스 연산을 통해 data.frame 내부 데이터에 접근하게 되는데, 인덱스를 벡터형식으로 주면 원하는 행과 열을 뽑아낼 수 있다. 물론 이런 형식의 연산은 대부분의 데이터형에서 적용된다. 게다가 인덱스 자체를 불(boolean) 값을 통해 접근할 수 있다. 그러니까 인덱스에 TRUE 값이 걸린 값들만 추출할 수 있다. 앞의 예에서 ① df[df$z,]가 이와 관련된 연산이 된다.
②번 마지막 명령어를 자세히 보면 k라는 열을 추가하는데, 단순히 할당 연산자만을 갖고 열을 추가할 수 있음을 알 수 있다. 특정 행이나 열을 변환하고 또 기존 데이터에 붙이고, 자르는 연산이 데이터 분석에서는 빈번히 일어나게 된다. R에서는 이런 연산들이 굉장히 직관적이고 간편하게 수행되는 것을 볼 수 있다.
data.frame은 여러 개의 같은 길이를 가진 벡터자료형을 결합해 놓은 형태로 보면 된다. list는 길이도 다르고 타입도 서로 다른 데이터를 포함할 수 있는 데이터 형태다. list에 대한 간단한 예는 다음과 같다.
|
> e <- list(kind=”dog”, age=5) > e$kind [1] “dog” > e[1] $kind [1] “dog”
> e[[1]] [1] “dog” > e[[2]] [1] 5 > g <- list(“이 > g [[1]] [1] “이
[[2]] [[2]]$kind [1] “dog”
[[2]]$age [1] 5 |
사실 데이터를 처리하다 보면 각 행이나 열에 특정 함수를 적용해 새로운 데이터 객체를 만들 경우가 상당히 많다. 이런 부분들을 다루기 위해서는 apply 유형의 함수를 찾아보기 바란다. 함수형 프로그래밍 경험이 있다면, apply 유형의 함수는 상당히 편하게 접근할 수 있지만 본 주제의 범위를 넘어서는 것이라서 여기서 설명은 생략한다.
R help 시스템
무엇보다 R 시스템은 방대하기 때문에 알고 싶은 것을 빨리 찾아보는 방법을 알아둘 필요가 있다.
Class함수에 대한 매뉴얼을 보고 싶다면, ‘?class’ 명령을 콘솔에 입력하거나 help(“class”) 명령을 입력해 매뉴얼을 확인 할 수 있다. 매뉴얼이 처음엔 눈에 잘 들어오지 않을지 몰라도 R을 활용하기 위해 가장 많이 참고하게 되는 문서 세트다. 특히 ‘see also’ 부분은 자신이 입력한 함수나 데이터와 관련된 것들을 보여 준다. 이를 통해 다양한 관련 함수를 알아볼 수 있다. 그리고 만일 함수명을 모르고 교과서에 나온 어떤 개념과 관련된 함수를 찾고 싶다면 어떻게 할까. ??”XX” 형태의 명령을 주면 찾아준다. 예를 들어 “normality test”와 관련된 함수를 찾으려면 ??”normality test”라고 입력하면 shapiro test 함수를 보여준다. 물론 아쉽게도 한글 매뉴얼은 없다.
이런 종류의 help계열의 함수들은 다음과 같다.
<표 2>help 계열의 함수 목록
|
함수 |
설명 |
|
help(“mean”) 또는 ?mean |
Mean함수에 대한 매뉴얼을 보여줌 |
|
help.search(“mean”) or ??mean |
mean이라는 단어를 찾아 관련 매뉴얼을 보여줌 |
|
example(“mean”) |
함수가 어떤 식으로 사용되는지 사용 예를 보여줌 |
|
RSiteSearch(“mean”) |
메일링 리스트와 같은 온라인 리소스에서 관련 문서를 찾아줌 |
|
data() |
현재 환경에서 로드된 예제 데이터들의 목록을 보여줌 |
|
vignette() |
비네트라는 소개 문서들의 목록을 보여줌. 이때 일반적으로 유명한 패키지들은 이 문서를 포함하고 있으며, 참고 시 많은 도움이 됨 |
|
vignette(“twitteR”) |
twitteR이라는 트위터 패키지의 비네트를 보여줌.이때 twitteR 패키지가 설치돼 있어야 함 |
R 워크스페이스
R을 실행하면 현재 작업 경로를 기준으로 워크스페이스를 만든다. 따라서 R콘솔을 열고 작업을 하다가 콘솔을 종료하면 그동안 작업 결과를 저장해도 되는지 확인하는 창이 뜬다. ‘저장’을 선택하고 종료하면, 다음 실행시 동일한 작업환경에서 계속해서 작업할 수 있다. 이 때 이전에 만들어 둔 data.frame, list, vector 등의 데이터들과 각종 변수들이 그대로 되살아난다.
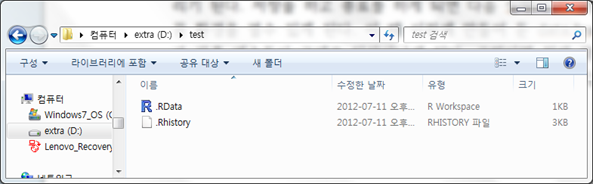 <그림 5> 워크스페이스 저장으로 남는 파일들
<그림 5> 워크스페이스 저장으로 남는 파일들
<그림 5>에서 .RData가바로 사용된 모든 변수 및 데이터를 저장하고 있는 파일이며, .Rhistory는 사용자가 입력했던 명령어 내역을 저장하고 있다.
그렇다면 현재의 작업 경로를 알 필요가 있다. 이를 확인하기 위해 ‘getwd()’ 명령어를 사용하면 된다. 그리고 현재 작업 경로를 바꾸고 싶다면 ‘setwd(path)’를 이용해 바꾸면 된다.
RStudio에서는 이런 워크스페이스를 프로젝트 단위로 관리할 수 있는 편리한 환경을 지원한다.
R 콘솔의 워크스페이스를 관리하는 함수들은 다음과 같다.
<표 3>R 콘솔의 워크스페이스를 관리하는 함수 목록
|
함수 |
설명 |
|
getwd() |
현재 작업 경로 반환 |
|
setwd(“mydir”) |
현재 작업 경로는 mydir로 변환 |
|
ls() |
현재 워크스페이스에 존재하는 객체 리스팅 |
|
rm(someObjects) |
객체 삭제(주로 가용 메모리 확보를 위해 사용) |
|
history() |
명령어 이력 리스팅 |
|
savehistory(“file”), loadhistory(“file”) |
이력 저장 및 로딩 |
|
save.image(“file”) |
워크스페이스를 파일로 저장 |
|
load(“file”) |
현재 세션에 워크스페이스 로딩 |
|
q() |
R 세션 종료 |
여담이지만, 현재 워크스페이스의 모든 객체를 삭제하는 명령은 “rm(list=ls())”이다. 사실 “rm()”으로 대량의 데이터를 지울 때는 메모리를 확보하기 위한 경우가 대부분인데, 이후에 “gc()”라는 가비지컬렉션 함수를 명시적으로 호출해주는 것이 좋다.
패키지 시스템
패키지를 인스톨한다는 것은 패키지를 다운받고 이를 라이브러리 경로에 설치하는 것을 의미한다. 만일 ggplot2패키지를 설치하고자 한다면 다음 명령어를 입력하면 된다.
|
>install.packages(“ggplot2“) |
이 명령어 입력 시 가끔 CRAN 미러링 서버를 지정하라는 말이 나오는데, 독자의 위치에서 지리적으로 가장 가까운 미러링 서버를 선택하면 된다.
그리고 설치된 패키지를 현재 워크스페이스에서 사용하기 원한다면, 다음 명령어를 사용하면 된다.
|
>library(ggplot2) |
이런 패키지들은 “.libPaths()”명령어 실행으로 나오는 경로에 설치된다.
R 문법
마지막으로 설명할 부분은 R 문법이다. 사실 R의 모든 문법에 대해여기서 설명할 수는 없다.따라서 죽 따라 읽어가면서 이해할 수 있는 수준으로 간단히 소개한다. 따라서 더 자세한 설명은 R관련 문법책을 따로 참고하는 것을 추천한다.
R에서 상수는 데이터 객체의 근간을 이루는 것들이다. 예를 들어 숫자, 문자, 심벌(symbol)들을 상수라 한다.
여기서 심벌은 다른 객체를 가리키는 객체를 의미한다. 일반적으로 변수라는 것이 그것이다. 변수를 상수하라고 하는 게 이상하지만 변수가 될 수 있는 심벌은 한정돼 있고, 이들이 어떤 객체를 가리키는지는 가변적이라고 생각하면 된다.
연산자는 앞서 잠깐 설명을 했다. R에서는 많은 함수들이 연산자로 재정의될 수 있다. 예를 들면 + 연산자 매뉴얼과 코드는 다음과 같다.
|
> ?`+` > `+` function (e1, e2) .Primitive(“+”) |
“e1, e2” 인자를 받는 함수 형태로 돼 있는 것을 볼 수 있다.
이러한 연산자는 연산 순서를 갖게 되는데 연산순서에 대한 요약은 다음과 같다. 상위에 있을수록 연산 순위가 높다.
1. 함수 호출 및 그룹 연산자 (‘()’, ‘{}’)
2. 인덱스 연산자 (‘[]’, ‘[[]]’)
3. 특수 연산자 (‘%*%’)
4. 수치 연산자 (‘-‘, ‘+’)
5. 비교 연산자 (‘<>’, ‘==’)
6. 식(formulas) (‘~’)
7. 할당 연산자(‘<-‘, ‘<<-‘)
8. Help(‘?’)
Expression은 콘솔에서 명령어를 입력하는 단위라고 생각하면 된다. 물론 그런 명령어는 엔터키로 인해 ‘new line’이 입력돼 하나의 Expression이 실행되는 형태지만, 여러 개의 Expression을 세미콜론으로 엮어 한 라인에 표현할 수도 있다.
|
>y<- 1 >z<- 2 >k<- 3 >y<-1 ; z <- 2 ; k <- 3 |
괄호는 Expression의 수행 결과를 리턴하며, 대괄호의 경우 여러 개의 Expression을 수행할 수 있게 한다.
|
> (y<- 1) [1] 1 > {y<-1 ; z <- 2 ; k <- 3; y+z+k} [1] 6 |
R의 제어문은 대부분의 프로그래밍 언어에서 제공하는 그것과 매우 유사하다.
If문의 경우 다음과 같은 형태를 띤다.
if(조건식) 참일 때 실행하는 Expression else 거짓일 때 실행하는 Expression
또는 아래와 같이 간단한 형태일 수 있다.
if(조건식) 참일 때 실행하는 Expression
한 가지 기억할 것은 ‘조건식’부분에 앞서 언급한 벡터화가 적용되지 않는다는 것이다.
따라서 벡터에 대한 조건 검정을 해야 한다면 “ifelse()” 함수를 사용해야 한다.
|
>x<- 3 >y<- c(1:10) >if(x < y) x else y [1] 1 2 3 4 5 6 7 8 9 10 경고 In if (x < y) x else y : 조건 >ifelse(x < y, x , y) [1] 1 23 3333333 |
반복문에는 repeat, while, for문이 있다.
repeat문은 아래와 같은 형태를 띈다.
repeat Expression
내부의 Expression문에 대해서 break문이 나올때까지 반복한다. 다른 언어에서 continue에 해당하는 문이 next문인데, 이것은 다음 루프로 건너뛰게 하는 역할을 한다.
while문은 아래와 같은 형태를 띤다.
while (조건식) Expression
내부의 조건식이 참일 동안에 Expression을 계속 수행하는 역할을 한다.
물론 while문 내부에서도 next와 break를 사용할 수 있다.
마지막으로 for문이다.
for(variable in list(vector)) Expression
각 list나 벡터의 내부 원소들을 순회하면서 그 원소를 이용한 연산을 수행하게 된다. 따라서 반복은 내부 원소 개수만큼 하게 된다.
위 세 예제는 다음과 같다.
|
>i<- 0 >repeat {if(i>= 5) break else i<- i + 1; print(i)} [1] 1 [1] 2 [1] 3 [1] 4 [1] 5 >i<- 0 >while(i<= 5) {i<- i + 1; print(i)} [1] 1 [1] 2 [1] 3 [1] 4 [1] 5 [1] 6 >vec<- c(1:10) >for(i in vec){print(i)} [1] 1 [1] 2 [1] 3 [1] 4 [1] 5 [1] 6 [1] 7 [1] 8 [1] 9 [1] 10 |
R에서 함수를 만드는 방법은 같은 방법을 쓴다.
function(arguments) body
arguments는 심벌들로 구성되며, body는 Expression을 의미한다. 일반적으로 body는 대괄호로 둘러싸이는데, 다수의 Expression으로 구성될 때 그렇게 쓰인다.
아래 함수들은 같은 결과를 보여준다.
|
>f<- function(x,y) x + y >f<- function(x,y) { x + y } |
위의 함수를 보면 return문도 없는데 리턴값을 보내준다. 일반적으로 R 함수에서는 가장 마지막의 Expression이 수행된 결과를 리턴한다. 그러나 명시적으로 return문을 넣어주는 습관을 갖는 게 좋다.
지금까지
R 언어의 여러 특징들을 간단히 살펴보았다. 어떤 프로그래밍 언어든 문법을 이해하려면 수고가 따른다. 여기에 소개된 내용보다 훨씬 많은 R에 대한 내용이 공개돼 있다. 아마도 이번 호의 튜터리얼을 보고 ‘R 언어의 특징이 이런 거구나’ 하는 정도만 알아도 큰 소득이지 않을까 싶다.
사실 R을 공부하기 위한 자료는 정말 많다. 굳이 이 과정을 소개한 것은 앞으로 제시할 내용들이 이 문법을 기반으로 하기 때문이다. 그리고 이번 R 튜토리얼에서 설명되지 않은 문법적인 부분들은 앞으로 각각 주제들을 진행하면서 그때그때 설명하겠다.
<참고자료>
※ Referenced from “R in a nutshell”, “R in Action” and “R workshop for beginners(http://www.slideshare.net/metamx/r-workshop-for-beginners)”