
안녕하세요. 고감자 입니다. 블로그에서는 오랜만이네요. 한창 블로그를 많이 쓰던 때에 비교하면 거의 블로그는 방치 상태였는데, 그럼에도 불구하고 글쓰기의 묘미는 여전히 있다고 생각합니다. 그리고 공개되는 글이 없는 반면에 제가 개인적으로 정리하고 메모하는 글을 상당합니다. 그런데, 그러한 글들은 거의 공유되지 못하고 죽어버린 정보가 되는 경우가 많다는 생각이 들었습니다. 따라서 올해부터는 개인적으로 정리하고 소화하는 정보를 블로그에 정리해보고자 합니다. 뭐 일종의 뉴스레터 같은거라 생각합니다. 아마도 이 뉴스레터는 개인적인 관심사 위주로 흘러갈 거라서 아마도 같은 관심사를 가진 분들에게는 큰 도움이 될수도 있을 것입니다.
정리는 기술단위로 진행하겠습니다만, 이번 주제는 요즘 핫한 큰 모델 학습하기…(GPT-3…)…
ZeRO, Pipe Model Parallel
10억개 정도 파라메터를 가진 모델은 V100 GPU 한장에서 파인튜닝이 불가능하다. 이를 가능하게 하는 여러가지 기술이 소개되고 있는데, 이에 대한 내용을 정리해 본다.
DeepSpeed는 GPU 메모리를 획기적으로 줄이면서 학습 효율을 높이는 기술(ZeRO, Offload)을 제공하고 있고, FairScale은 DeepSpeed의 ZeRO(stage 1)과 GPipe의 Pipe Parallel 기술을 PyTorch API로 잘 정리해서 제공하고 있다. 이 기술(ZeRO)가 transformers trainer에 포함되었다는 포스팅인데, 역시 Transformers는 기술들을 민주화하는 역량이 상당한것 같음.
위 글의 내용을 포함해서 다양한 논의들이 이곳에서 진행되고 있으니 관심 있으신 분들은 구독!
PyTorch Lightning은 간편한 사용과 다양한 기능 덕분에 필자도 애용하는 학습 프레임웍. Facebook의 Production에서도 기본 학습 프레임웍으로 사용하고 있다고함.
- PyTorch Lightning 1.1 – Model Parallelism Training and More Logging Optionn
- Introducing PyTorch Lightning Sharded: Train SOTA Models, With Half The Memory
PyTorch Lightning은 Facebook Research의 FairScale를 채용해서 앞서 설명한 ZeRO와 GPipe의 Pipe Model Parallel을 적용해 학습하는 방법을 소개하고 있다. 필자도 빠르게 사용해 봤는데, ZeRO의 경우 잘 동작하나 Pipe Model Parallel은 몇가지 이슈가 있었음. 특히 필자가 올린 이슈는 해결이 쉽지 않아 보였는데, 빨리 해결되길 바람.
곧 PyTorch에 포함된 ZeRO를 보게될거 같음. 하지만 아직까지는 빅 모델 학습의 끝판왕은 Megatron-LM임. 학습은 잘 하시더라도 학습된 모델 잘들 사용하고 있는지? :\
torch.utils.data.DataLoader 부분을 잘 사용하는것은 생각보다 중요합니다. 특히나 대용량의 데이터를 효과적으로 다룰때는 내부가 어떻게 동작하는지 이해하는건 매우 중요함. 위 git에서는 아주 간단한 dataloader를 직접 만들어 보면서 그 구현 원리를 파악하고 있음. 관련된 블로그 글도 있으니 참고!
QA
- Retrieval Augmented Generation with Huggingface Transformers and Ray
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
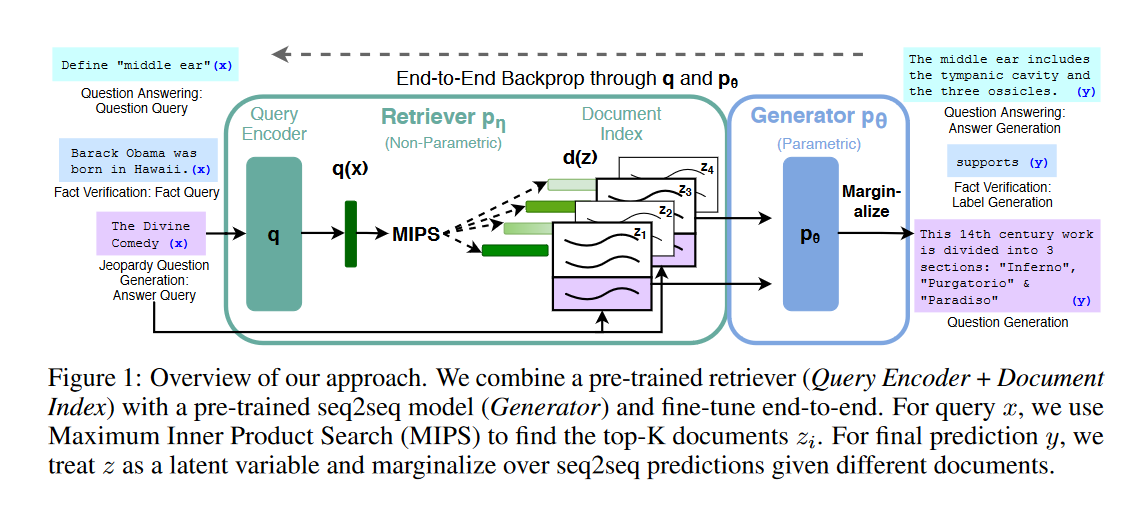
GPT같은 모델에서 원하는 방향으로 생성을 잘 하려면 context를 잘 줘서 생성해야 됨. 언어모델 학습때 사용한 위키로 관련 정보를 보강해서 context를 만들어 줄 수 있으면 생성시 좋은 효과를 볼 수 있는데 특히 QA와 같은 knowledge-intensive 테스크에서 좋은 성능을 보여줌.
Model Serving
필자의 경우 주로 cortex 사용해서 모델 API를 제공해왔음. 이를 활용한 이유는 인스턴스 성능에 따라 모델의 출력(throughput) 조절하기가 간단했기 때문임(전통적인 멀티프로세싱으로 인한 스케일링…방식).
BentoML은 MLOps분들이 좋아할만한 플랫폼임. 다양한 모델을 커버하고 있고, 모델 버전관리를 하는 레포지터리의 UI는 가장 맘음에 든다. 그리고 모델 인퍼런스 성능에 영향을 주는 micro batching을 적용해 response time 최적화가 가능하다는 큰 장점이 있음.
Research
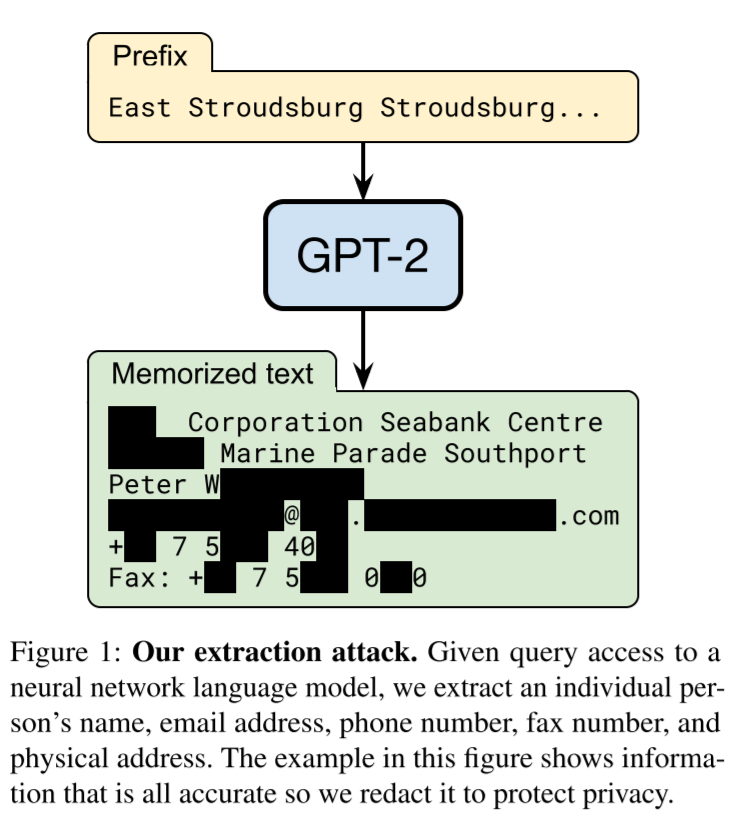
학습때 사용한 데이터를 언어생성할 수 있다는 건데, 문제는 민감 정보가 포함될 수 있다는 것임. 이를 위해 학습 데이터에 일종의 노이즈를 가해서 생성하는 차등정보보호(Differential Privacy)와 같은 조치와 더불어 학습 데이터를 문서 이하 레벨로 중복필터을 하는 방식을 제안하고 있다. 중복필터가 중요한 이유는 이러한 공격(attack)이 모델의 과적합과 관련이 되있다고 보기 때문임.
통계청에서 공유하고 있는 차등정보보호 관련 발표자료.
lable semantics + generation 를 이용한 서로 다른 테스크(NLU)들 사이의 knowledge sharing, few shot 성능 좋음, T5 활용(BART도 가능할 것으로 판단). 인코더, 디코더 모델의 실무 활용성을 가늠해볼 수 있는 논문입니다.
generation 모델 학습시 단순한 auxiliary tasks 추가만으로 더 좋은 생성 결과를 보여줬다. auxiliary task 는 인코더 디코더 학습시 인코더에 넣는 방식으로 해서 확장 가능하다. 코퍼스 성격에 따라 다르나, order recovery , content recovery(MLM) 모두 NLG에 중요한 task임.디코더가 단순해 빠른 생성이 가능. 성능 좋은 인코더가 있을 경우 빠르게 NLG 성능을 올릴 수 있는 방법임
인코더 MLM with RoBERTa (autoencoding). 디코더 NS Generation + pointer generator (autoregressive generation). 잘 학습된 인코더만 있을 경우 NLG를 잘 할 수 있는 모델을 찾는데 의미가 있음.. 성능은 그럭저럭

