
띄어쓰기는 형태소 분석 이전에 반드시 수행해야 되는 중요 전처리 과정중에 하나이며, 이 때문에 공개된 형태소 분석기에는 일종의 자동띄어쓰기 모듈이 숨겨져 있는 경우가 많다. 하지만 그런 띄어쓰기 엔진의 성능이 대부분 좋지 않아 허울뿐인 경우가 많다. 필자가 만든 KoNLP 역시 그중에 하나였다.
물론 띄어쓰기는 형태소 분석 이전에만 사용하는게 아니다. 띄어쓰기 모듈은 Speech To Text 혹은 음성인식 모듈에서 출력된 텍스트들에 대한 정제를 할때 후처리용으로 반드시 쓰이게 되는 모듈이다.
이런 저런 개발과정을 거친 후 약 1년 가까이 구글 클라우드에서 REST API 형태로 제공을 하고 있었고, 일 평균 10만 쿼리를 처리하던 와중, 클라우드 캐시가 동나버려서 어떻게 할까 고민을 하던 결과 KoSpacing 패키지로 공개하게 되었다. 딥러닝을 좀 하셨던 분들은 아시겠지만 아래와 같은 독특한 아키텍처를 가지는 모형 자체를 포함하고 있는 자동 띄어쓰기 패키지이다.
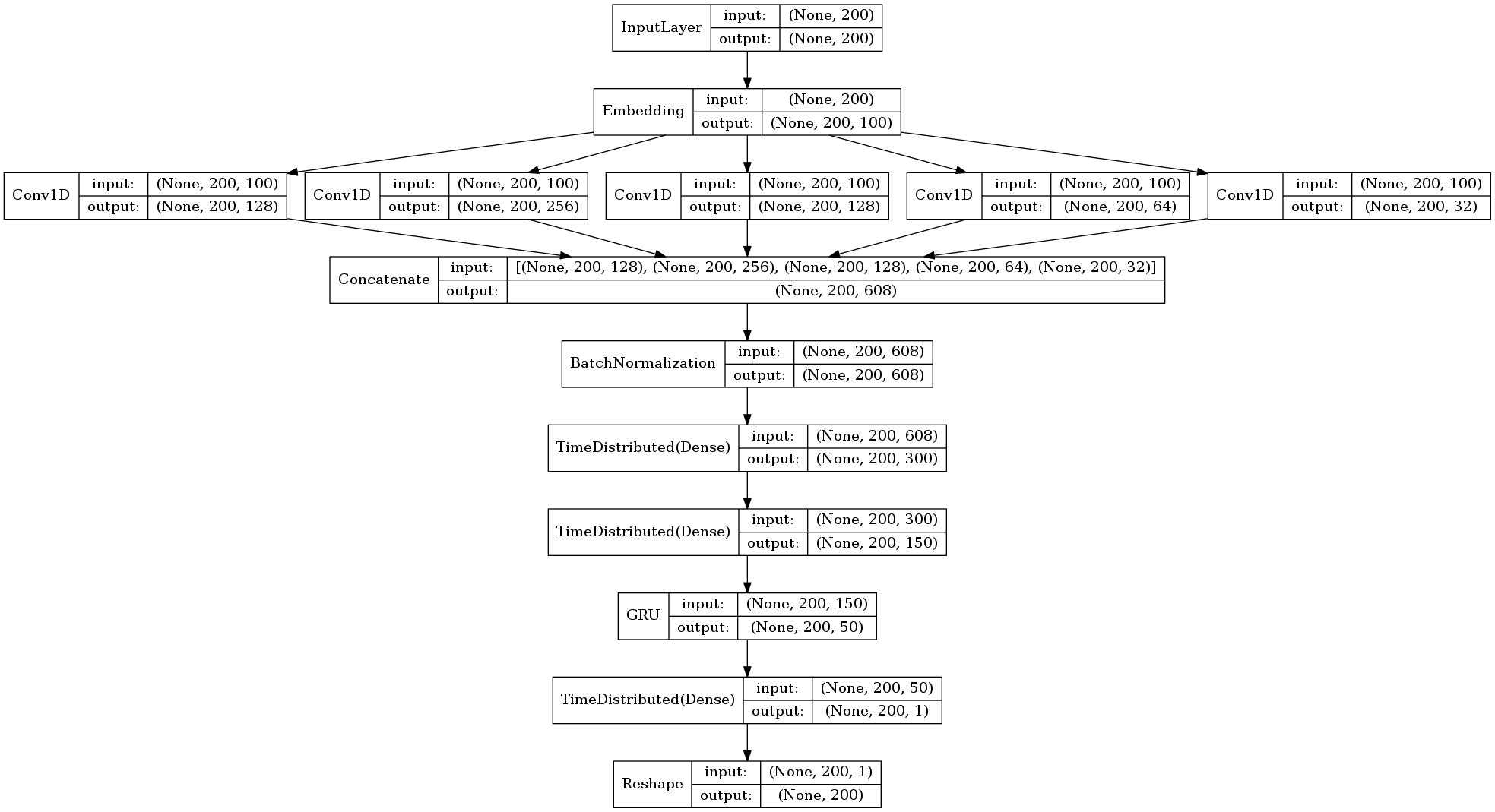 Neural Ngram Detector Architecture
Neural Ngram Detector Architecture
이 아키텍처를 찾아내느라 생각보다 많은 시행착오를 했는데, 결국은 N-Gram을 어떻게 자동으로 학습 할 것인가가 성능을 크게 향상시키는 동력이 되었고 기존의 N-Gram에 대한 임베딩을 직접해서 하는 방식보다는 위에서 보는것과 같이 1D Convolution을 활용해서 사람이 직접 N-Gram을 인코딩하는 수고를 덜었고, 네트웍에서 직접 학습이 될 수 있게 구조화 하였다. 실제 필자가 실험해본 결과 LSTM-CRF 기반의 가장 성능이 좋다는 아키텍처에 필적하면서 오히려 N-Gram을 직접추출하지 않고 네트웍에서 직접 학습이 되게끔 하면서 기존 베스트 모형보다 모형 생성의 리소스를 줄였다는 성과가 있었다. 게다가 마지막 레이어에 CRF도 쓰지 않았다.
위 아키텍처는 작년 10월 버전으로 Keras로 학습되었으며, 현재 보다 적은 데이터로 위 모형보다 더 좋은 성능을 내는 아키텍처를 실험하고 있는 상황이다. 보통의 공개된 레이어가 아닌 다소 커스터마이징된 레이어가 필요해 MXNet Gluon으로 실험하고 있고, 논문 결과로 정리중이다.
KoSpacing 패키지는 개인적으로 의미가 있는 패키지인데, 이 패키지는 필자가 만든 최초의 Model as a Program 으로 패키지 내부에 로직이 존재하지 않고 바이너리 덩어리(모델파일)로 존재한다. 소프트웨어 자체에 로직이 직접적으로 포함된게 아니라 들여다 보기 어렵고 관리하기 어려울 수 있지만, 기존의 소프트웨어 로직으로 가능하지 않던 성능을 내는 소프트웨어를 이런 Model as a Program으로 만들어낸다면, 좀더 편안한 소프트웨어 세상이 되지 않을까 하는 생각을 해본다.