
최근 필자가 논문 리딩을 하는 와중에 클래스 불균형 문제(예측 대상이 되는 부류의 비율이 현저히 달라 생기는 문제)에 대한 논문을 보게 되면서 잠시 이쪽 방향에 대한 고민을 할 기회가 있었다. 실무적으로 많은 예측 업무가 몇개의 클래스들이 심하게 불균형된 상황에서 진행되다 보니 습관적으로 major class에 대한 under sampling을 통한 50:50 학습셋 비율을 맞추는 방향으로 업무를 진행했던게 사실이다. 물론 이 기준 역시 필자 경험에서 나온 나름의 기준이었다(이 때문에 팀내 많은 분들이 비판없이 이 방식을 따르는 폐해가 있긴 하지만…ㅠㅠ ). 하지만 이 기준이 맞는지는 한번도 생각해볼 기회가 없었던게 사실이다. 왜냐면… 데이터가 많았고…그런 고민을 할 만한 동기가 없었다.
클래스 불균형 문제가 왜 큰 문제인가 하면 …
- major class를 잘못 예측하는 것보다 minor class를 잘못 예측하는 것의 비용이 일반적으로 더 크다.
- 많은 경우 예측 정확도(accuracy)를 기반으로 예측 성능을 평가한다는 문제
- 전체 90%는 넘게 차지하는 major class를 예측하는건 상대적으로 매우 쉬운 일이다. 왜냐면 모든 데이터를 major class로 예측하면 90% 정확도는 확보 되기 때문이다. ㅎㅎ
과연 내가 잘 하고 있는가 하는 고민의 시발점이 되었던 논문[1]의 표가 있는데, 이를 확인해보면 아래와 같다.
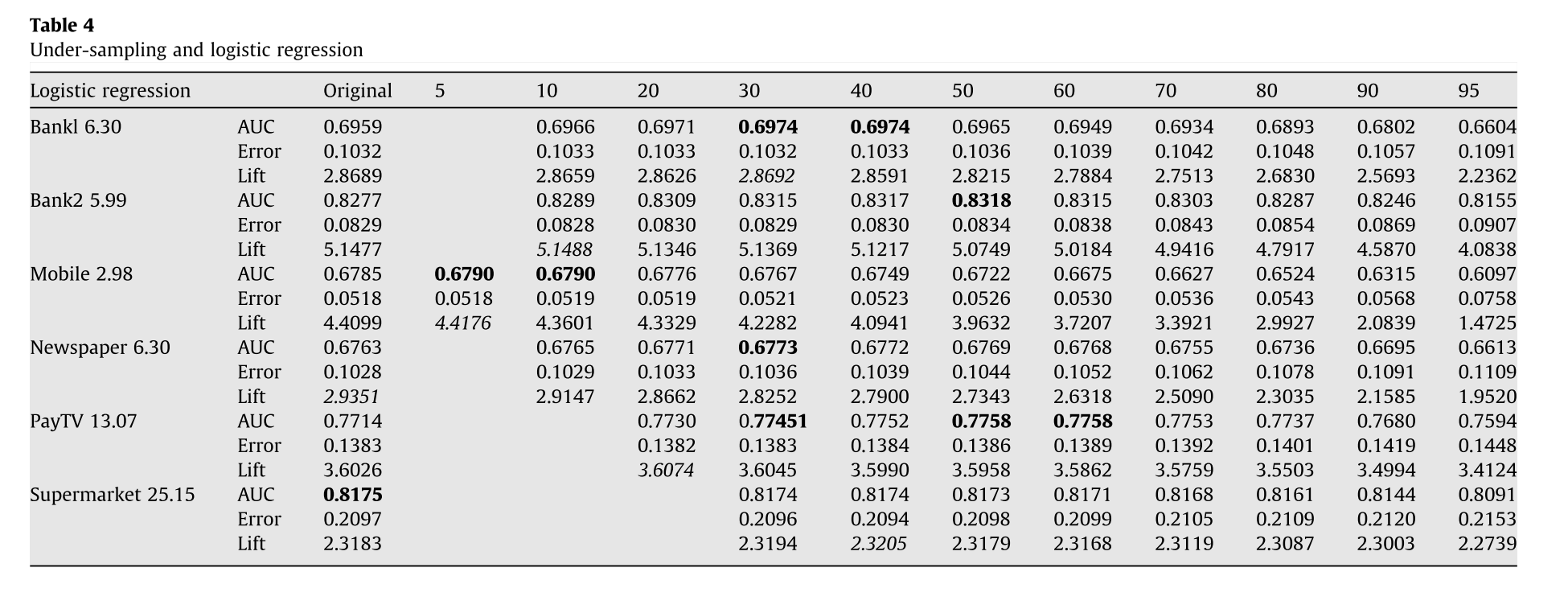 여러가지 셋에서 검증한 결과 결코 major class를 minor class와 같은 비율로 언더 샘플링을 한게 결코 최적의 결과가 아니라는 것을 보여준다. 이는 로지스틱 회귀 관련 표였으나, 논문을 보면 randomForest 역시 유사한 현상이 일어나는 것을 알 수 있었다.
여러가지 셋에서 검증한 결과 결코 major class를 minor class와 같은 비율로 언더 샘플링을 한게 결코 최적의 결과가 아니라는 것을 보여준다. 이는 로지스틱 회귀 관련 표였으나, 논문을 보면 randomForest 역시 유사한 현상이 일어나는 것을 알 수 있었다.
몇몇 연구들을 종합해보면, 일반적으로 under sampling과 training set에 weight을 주는 방식으로 회피하는 방안이 그나마 다른 것들보나 좋은 결과를 보여주고 있다고 하고 많은 분들이 알고 있는 SMOTE 방식과 같은 인공적으로 데이터를 생성하는 방식은 후행 연구들의 비판을 많이 받았다.
그 와중에 필자의 눈을 확~ 잡아당기는 방식이 있었으니, 그것은 앙상블에 기반한 방식[2]이었다.
어느정도 언더 샘플링을 해야 되는지 기준을 모르겠다면 여러번 셋을 만들어 앙상블 방식으로 결정하게 하면 된다는게 핵심 아이디어이다.
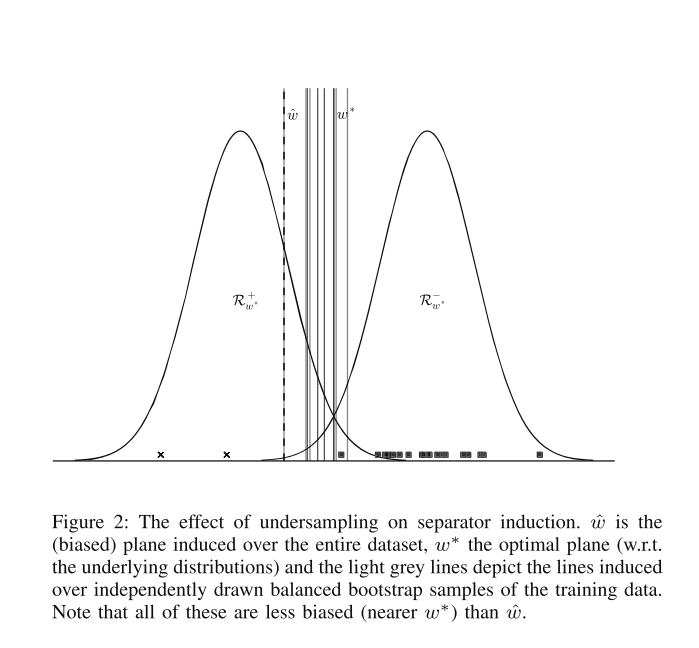 위 그림에서 방법론의 아이디어가 도출되었는데, 결국 N개 개별의 balanced bootstrap sample(boostrap sampling 이후 50:50의 비율로 언더 샘플링을 해서 얻는 학습셋)로 N개의 분류기를 만들고 이들의 예측치를 기반으로 예측을 하자는 이야기다. 개인적으로 이 방식은 Breiman교수님의 Balanced Random Forest의 개념과 매우 흡사하다고 생각하고 또한 weighted Random Forest와 맞닿아 있지 않나 하는 생각도 들게 한다.
위 그림에서 방법론의 아이디어가 도출되었는데, 결국 N개 개별의 balanced bootstrap sample(boostrap sampling 이후 50:50의 비율로 언더 샘플링을 해서 얻는 학습셋)로 N개의 분류기를 만들고 이들의 예측치를 기반으로 예측을 하자는 이야기다. 개인적으로 이 방식은 Breiman교수님의 Balanced Random Forest의 개념과 매우 흡사하다고 생각하고 또한 weighted Random Forest와 맞닿아 있지 않나 하는 생각도 들게 한다.
이 방식 이외에 인공적으로 셋을 만드는 ROSE나 SMOTE 방식은 사실 컴퓨팅 파워만 쓰지 실무적으로 큰 효과를 보질 못했다. 물론 이러한 이야기는 이쪽 연구자들 사이에서도 왕왕 언급되는 부분이기도 하다.
뭔가 예측업무를 하려면 성능을 측정하는 metric을 정하는게 중요하다. 이걸 적절하게 정하지 않을 경우 흡사 나침반이 없이 여행하는것과 같다. 앞서 언급했지만 accuracy나 confusion matrix의 경우 심각하게 퍼포먼스를 왜곡할 가능성이 있으니 클래스 불균형 문제에서는 피하라 조언했었다. 이외에 사용할 수 있는 방법론은 아래와 같다.
- Lift
- AUC
- F1-mesure
- Cohen’s Kappa
위 방법론은 클래스 불균형 여부에 상관없이 일정한 퍼포먼스 인덱스를 제공해 주니 예측업무에서 빠질 수 없는 통계량이다.
아마도 필자가 50:50 비율로 클래스 비율을 맞춰 학습을 했던 이유는 오래전에 이런 방식으로 나은 성능이 도출된 경험이 있어서였을 거란 생각을 해본다. 하지만 그간 한번도 그 방법이 맞을까 의심해 보지 않고 있었다는 것에 나 자신도 놀랐다. 결국 골든룰은 없다는 것이고, 실제 업무를 한다면 샘플링 비율 자체를 cross validation을 통해 스스로 정해야 될 수 있다는 것을 의미할 수도 있다. 물론 이 고민들이 그만한 가치가 있을까 라는 이야기를 할 수 있으나, 예측 모델의 품질은 분석가의 자존심 이라고 생각하는 분들에게는 한번쯤 고민해봐야 될 문제라 생각한다.
Reference
-
Burez, J., & Van den Poel, D. (2009). Handling class imbalance in customer churn prediction. Expert Systems with Applications, 36(3 PART 1), 4626–4636. http://doi.org/10.1016/j.eswa.2008.05.027
-
Wallace, B. C., Small, K., Brodley, C. E., Trikalinos, T. A., & Science, C. (2011). Class Imbalance , Redux. http://doi.org/10.1109/ICDM.2011.33
안녕하세요 선생님~ ‘R로 하는 데이터 시각화’라는 책에 흥미를 느껴서 그거로 공부 중입니다! 자주 공부하러 오겠습니다~~
좋은 글 감사합니다 👍