
“gensim이 아닌 직접 딥러닝 네크워크 구조를 구현해 임베딩을 성공적으로 학습해본 경험이 있는지요?”
이 글은 네트워크 구조의 임베딩 학습을 숫하게 실패해본 분들을 위한 글이다.
많은 온라인 문서에서든 책에서든 word2vec을 설명하는 부분에서 딥러닝 프레임워크 기반 그래프 구조로 설명을 한다. 게다가 코드와 학습까지 Keras와 같은 프레임워크로 동작하는 예제를 제공하나, 추출된 단어 벡터를 기반으로 Word Analogy나 정성적인 평가에 대한 시도는 꼭 gensim과 같은 소프트웨어를 기반으로 학습한 벡터로 확인한다. 예를 들어 이러한 형태 말이다. 필자 역시 이런 저런 시도를 해본적이 있으나,과거 단 한번도 직접 네트워크를 만들어 gensim과 같은 퀄리티를 가진 임베딩을 생성해 본적이 없다.
최근에 큰 마음을 먹고 논문과 여러 글을 찾아본 결과 학습을 위한 중요한 몇가지가 빠져 있다는 사실을 발견했고, 이들 자료를 기반으로 Gluon으로 직접 활용 가능한 임베딩 학습 로직을 만들어 봤다.
이 글에서 Gluon기반의 NLP API[note]https://gluon-nlp.mxnet.io/[/note]가 유용하게 사용되었다. 아마도 글을 보면서 그 간결함을 느껴보는 것도 좋을 것이라 생각된다.
늘상 해왔듯이 세종 말뭉치 기반 학습을 수행했으며, 마침 한글 임베딩에 대한 검증셋도 얼마전에 구할 수 있어 검증셋으로 임베딩 평가를 했다. 그 셋에 대한 설명은 아래에서 설명할 것이다.
임베딩 학습
예를 들어 아래와 같은 문장으로 Skip-Gram(중심단어를 기반으로 주변단어를 예측하는)학습을 시킨다고 가정해보자.
명절이 다가오면 주부들은 차례/제사상에 올릴 배와 사과 등 과일에 눈이 갈 수밖에 없다.
간단하게 하기 위해 위와 같은 문장에서 명사만 추출해서 학습한다.
“명절, 주부, 차례, 상, 배, 사과, 과일, 눈, 수”가 명사로 추출될 것이다. 윈도 사이즈를 2로 하면 Skip-Gram 학습셋은 아래와 같이 구성된다(1은 두 토큰이 윈도우 내에서 존재할때의 레이블 값이다).
“명절, 주부, 차례, 상, 배, 사과, 과일, 눈, 수” -> (명절, 주부, (1)), (명절, 차례, (1))
“명절, 주부, 차례, 상, 배, 사과, 과일, 눈, 수” -> (주부, 명절, (1)), (주부, 차례), (1), (주부, 상), (1)
“명절, 주부, 차례, 상, 배, 사과, 과일, 눈, 수” -> (차례, 명절, (1)), (차례, 명절, (1)), (차례, 상, (1)), (차례, 배, (1))
…
“명절, 주부, 차례, 상, 배, 사과, 과일, 눈, 수” -> (사과, 상, (1)), (사과, 배, (1)), (사과, 과일, (1)), (사과, 눈, (1))
(사과, 과일)이라는 셋이 네트워크에서 학습되는 과정은 아래와 같이 내적계산을 기반으로 수행된다.
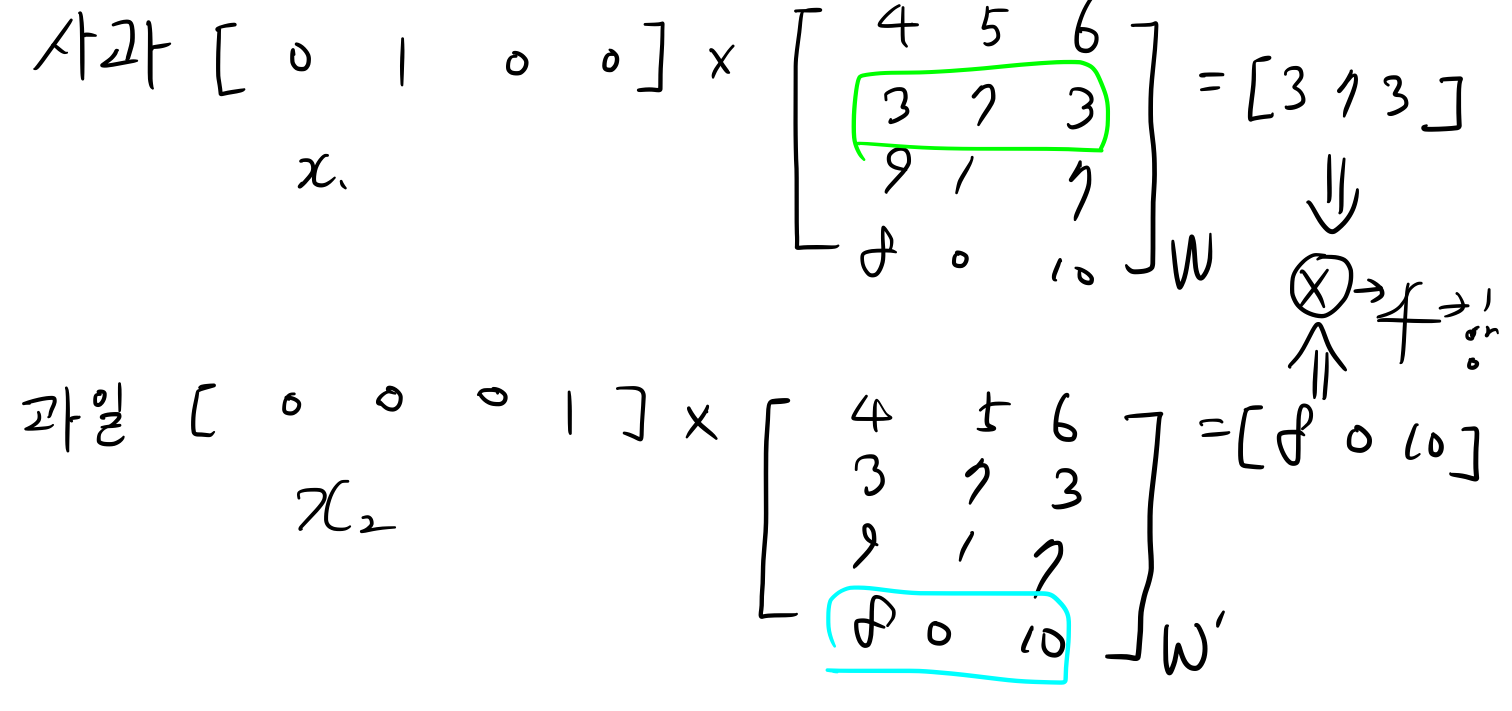
(사과, (상, 배, 과일, 눈, 고양이, 사자, 가을, 눈사람), (1,1,1,1,0,0,0,0))
그럼 word2vec을 학습하는 코드를 작성해보자. 역시 MXNet Gluon으로 작업했다.
이제부터는 핵심적인 코드 설명만 할 생각이다. 동작하는 전체 코드는 이곳에서 찾아볼 수 있다.
>> context_sampler = nlp.data.ContextSampler(coded=coded_dataset, batch_size=2048, window=5) >> negatives_weights = nd.array([counter[w] for w in vocab.idx_to_token]) >> negatives_sampler = nlp.data.UnigramCandidateSampler(negatives_weights)
ContextSampler는 Gluon NLP에서 제공되는 API로 입력된 데이터셋을 기반으로 배치를 만들어주는역할을 하며 주어진 윈도우 크기를 기반으로 주변단어와 주변단어 길이에 따른 마스킹을 중심단어와 함께 생성해준다. UnigramCandidateSampler는 우리가 구한 단어 빈도를 기반으로 샘플링을 수행하는 API이다. 네거티브 샘플들은 빈도에 기반해서 무작위로 생성되게 된다.
또한 자주 출현하는 단어들에 대해서 학습셋에 포함되는 확률을 줄여주기 위한 서브샘플링(subsampling)기법을 통해 학습의 효율을 획기적으로 올리는 기법도 사용된다. 이를 통해 학습 데이터 자체를 줄여주어 학습속도를 올릴 수 있게 된다.
서브샘플링 로직은 아래 수식과 같은 방식으로 샘플링 확률이 결정된다.
$$ P({ w }_{ i })=1-\sqrt { \frac { t }{ f({ w }_{ i }) } } $$
$ P(w_i) $가 작아야 학습셋에 들어갈 확률이 높아지는데, 여기서 $f(w_i)$는 단어의 출현 확률을 의미한다. 따라서 출현 확률이 낮은 단어일 수록 학습셋에 포함될 확률이 높아진다.
>> frequent_token_subsampling = 1E-4 >> idx_to_counts = np.array([counter[w] for w in vocab.idx_to_token]) >> f = idx_to_counts / np.sum(idx_to_counts) >> idx_to_pdiscard = 1 - np.sqrt(frequent_token_subsampling / f) >> coded_dataset = [[vocab[token] for token in sentence if token in vocab and random.uniform(0, 1) > idx_to_pdiscard[vocab[token]]] for sentence in sejong_dataset]
데이터와 전처리
학습에 쓰인 데이터는 세종코퍼스약 9만 4천 문장이며, Gluon NLP의 API를 통해 Vocab 객체로 변환한다. 토크나이저는 KoNLPy의 mecab을 사용했다.
>> sejong_dataset = nlp.data.dataset.CorpusDataset('data/training_corpus_sejong_2017_test_U8_norm.txt', >> tokenizer=lambda x:mecab.morphs(x.strip())) >> counter = nlp.data.count_tokens(itertools.chain.from_iterable(sejong_dataset)) >> >> vocab = nlp.Vocab(counter, unknown_token='<unk>', padding_token=None, bos_token=None, eos_token=None, min_freq=5)
모델
먼저 두개의 임베딩 레이어를 선언해준다. 이 레이어에서 생성된 가중치가 결국 우리가 원하던 word2vec 결과물이된다.
>> class embedding_model(nn.Block): >> def __init__(self, input_dim, output_dim, neg_weight, num_neg=5): >> super(embedding_model, self).__init__() >> self.num_neg = num_neg >> self.negatives_sampler = nlp.data.UnigramCandidateSampler(neg_weight) >> with self.name_scope(): >> #center word embedding >> self.w = nn.Embedding(input_dim, output_dim) >> #context words embedding >> self.w_ = nn.Embedding(input_dim, output_dim) >> >> def forward(self, center, context, context_mask): >> #이렇게 해주면 >> #nd.array를 선언시 디바이스를 지정하지 않아도 된다. >> #멀티 GPU 학습시 필수 >> with center.context: >> #주변단어의 self.num_neg 배수 만큼 비 주변단어를 생성한다. >> negs = self.negatives_sampler((context.shape[0], context.shape[1] * self.num_neg)) >> negs = negs.as_in_context(center.context) >> context_negs = nd.concat(context, negs, dim=1) >> embed_c = self.w(center) >> #(n_batch, context_length, embedding_vector) >> embed_u = self.w_(context_negs) >> >> #컨텍스트 마스크의 크기를 self.num_neg 만큼 복제해 값이 있는 영역을 표현한다. >> #결국 주어진 주변단어 수 * self.num_neg 만큼만 학습을 하게 된다. >> context_neg_mask = context_mask.tile((1, 1 + self.num_neg)) >> >> #(n_batch, 1 , embedding_vector) * (n_batch, embedding_vector, context_length) >> #(n_batch, 1, context_length) >> pred = nd.batch_dot(embed_c, embed_u.transpose((0,2,1))) >> pred = pred.squeeze() * context_neg_mask >> >> #네거티브 샘플들은 레이블이 모두 0이다. >> label = nd.concat(context_mask, nd.zeros_like(negs), dim=1) >> return pred, label
코드에서 특징적인 부분은 비 중심단어 생성을 위해 네거티브 샘플러를 쓰는 부분이다. Gluon NLP에서 잘 구현이 되어 있으니 감사히 쓸 수 밖에…
나머지 부분은 주석과 공식 API문서를 기반으로 생각해보면 큰 무리없이 이해가 가능할 것이다.
평가
임베딩 네트워크를 평가하는 방법은 사람이 스코어링한 단어의 관계 데이터를 기반으로 수행된다. 아쉽게도 지금까지 한글 임베딩에 대한 평가셋이 존재하지 않았으나, 최근 ACL Paper[note]http://aclweb.org/anthology/P18-1226[/note]에서 연구 데이터[note]https://github.com/SungjoonPark/KoreanWordVectors[/note]를 공개해 간편하게 평가해 볼 수 있게 되었다.
정답셋에 존재하는 단어쌍의 스코어가 우리가 만든 word2vec의 단어 유사도와 순위가 얼마나 같은지 Spearman Rank Correlation[note]https://en.wikipedia.org/wiki/Spearman%27s_rank_correlation_coefficient[/note]으로 평가한다.
>> import pandas as pd >> >> wv_golden = pd.read_csv('data/WS353_korean.csv') >> >> word1 = wv_golden['word 1'] >> word2 = wv_golden['word 2'] >> score = wv_golden['kor_score'] >> >> res = [[vocab.token_to_idx[i],vocab.token_to_idx[j],k] for i,j,k in zip(word1, word2, score) >> if vocab.token_to_idx[i] != 0 and vocab.token_to_idx[j] != 0] >> >> word12score = nd.array(res, ctx=ctx) >> >> word1, word2, scores = (word12score[:,0], word12score[:,1], word12score[:,2]) >> >> def pearson_correlation(w2v, word1, word2, scores): >> from scipy import stats >> evaluator = nlp.embedding.evaluation.WordEmbeddingSimilarity( >> idx_to_vec=w2v, >> similarity_function="CosineSimilarity") >> evaluator.initialize(ctx=ctx) >> evaluator.hybridize() >> pred = evaluator(word1, word2) >> scorr = stats.spearmanr(pred.asnumpy(), scores.asnumpy()) >> return(scorr)
Gluon은 임베딩의 워드 유사도를 계산해주는 함수를 제공하고 있고, 이 함수를 통해서 빠르고 간단하게 계산이 가능하다. 위 함수를 매 에폭마다 수행하게해 성능 향상 여부를 확인한다.
학습
>> from tqdm import tqdm >> >> ctx = mx.gpu() >> >> num_negs = 5 >> vocab_size = len(vocab.idx_to_token) >> vec_size = 100 >> >> embed = embedding_model(vocab_size, vec_size, negatives_weights, 5) >> embed.initialize(mx.init.Xavier(), ctx=ctx) >> >> loss = gluon.loss.SigmoidBinaryCrossEntropyLoss() >> optimizer = gluon.Trainer(embed.collect_params(), 'adam', {'learning_rate':0.001}) >> >> avg_loss = [] >> corrs = [] >> interval = 50 >> >> epoch = 70 >> >> for e in range(epoch): >> for i, batch in enumerate(tqdm(context_sampler)): >> center, context, context_mask = [d.as_in_context(ctx) for d in batch] >> with autograd.record(): >> pred, label = embed(center, context, context_mask) >> loss_val = loss(pred, label) >> loss_val.backward() >> optimizer.step(center.shape[0]) >> avg_loss.append(loss_val.mean().asscalar()) >> >> corr = pearson_correlation(embed.w.weight.data(), word1, word2, scores) >> corrs.append(corr.correlation) >> print("{} epoch, loss {}, corr".format(e + 1, loss_val.mean().asscalar()), corr.correlation)
코드는 학습 레이블이 forward()함수에서 생성된다는 것을 제외하고는 일반적인 학습 로직과 같다. 많이 쓰이는 Adam 옵티마이저를 사용하고 약 70 에폭을 학습했다.
학습 중 매 에폭마다의 상관관계를 시각화한 결과이며, 예상대로 상승하는 추세이며 약 0.5의 상관관계까지 상승하는 것을 알 수 있다.
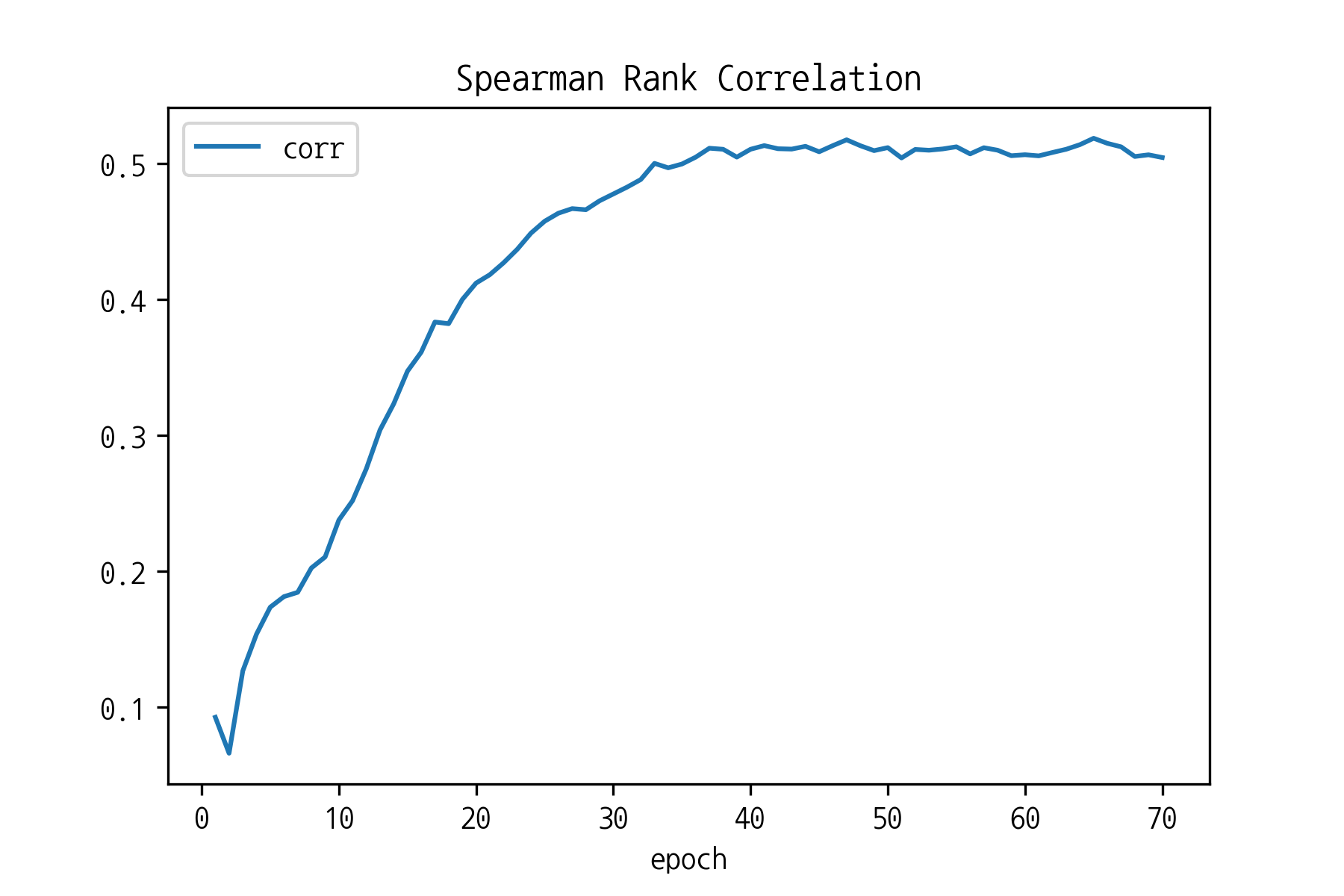
논문에서 훨씬 더 많은 학습셋과 Skip-Gram으로 약 0.59의 상관관계까지 도출된 것에 비교하면 어느정도 만족할 만한 수준의 임베딩이 학습된 것을 알 수 있다.
전체 코드와 데이터는 이곳에서 확인할 수 있다.
https://gist.github.com/haven-jeon/6b508f4547418ab26f6e56b7a831dd9a
References
- https://arxiv.org/abs/1301.3781
- http://gluon-nlp.mxnet.io/examples/word_embedding/word_embedding_training.html