
GluonNLP
NLP쪽에서 재현성의 이슈는 정말 어려운 문제이다. 실제 모형의 아키텍처와 적절한 전처리 로직이 잘 적용 되었을때 성능이 도출되나 대부분 리서치에서는 전처리 로직에 대한 충분한 설명이 되어 있지 않다. 따라서 아키텍처의 이해보다는 전처리에 대한 문제 때문에 후속 연구가 진행되지 못하는 경우가 많다.
전처리의 이슈가 큰 또 다른 이유는 처리 로직의 복잡도 때문에 같은 로직이더라도 다양한 구현 방식이 가능하다. 예를 들어 불용어 처리를 했다는 언급에는 어떠한 기준으로 용어를 필터링 했는지에 대한 다양한 질문들이 포함되어 있다. 이러한 아픔을 공감한 개발자들이 GluonNLP라는 프로젝트를 진행하고 있는데, 이 결과물을 기반으로 얼마나 쉽게 어텐션을 구현할 수 있는지 살펴보고자 한다.
어텐션 뿐만 아니라 다양한 언어모델과 이를 간편하게 사용할 수 있는 인터페이스 그리고 임베딩 모델을 제공하고 있으며, SOTA를 실행해 볼 수 있는 다양한 스크립트도 제공하고 있다. 특히나 언어모델, 임베딩 학습에 대한 시작과 활용의 시발점으로 하기에 매우 좋은 함수들도 제공하고 있어 이를 이해하고 사용하는 것 만으로도 큰 배움을 얻을 수 있다.
어텐션(Attention)
먼저 어텐션의 출현 배경을 설명하기 위해 일반적인 시퀀스 to 시퀀스의 구조를 살펴보자(이미 어텐션을 잘 아시는 분은 다음으로 넘어가도 된다).

인코더 정보를 디코더에 전달할 수 있는 방식은 고정된 길이의 짧은 히든상태 벡터이다. 이 히든상태 벡터는 디코더의 히든상태 입력으로 활용된다. 학습이 잘 되었다면 이 벡터에는 입력 문장에 대한 훌륭한 요약 정보를 포함하고 있을 것이다. 초기 신경망 번역기는 이러한 방식으로 구현되었는데, 입력 문장이 길어지면서 심각한 성능저하가 일어나기 시작했다. 이 짧은 히든상태 벡터에 긴 시퀀스의 정보를 모두 저장하기엔 한계가 있었으며, 이러한 문제의 해결을 위해 어텐션 개념이 만들어졌다[note]https://arxiv.org/pdf/1409.0473.pdf[/note].
어텐션은 RNN과 같이 딥러닝 관련 레이어가 아니라 매커니즘으로, 특정 시퀀스를 출력하기 위해 입력 시퀀스의 어떠한 부분을 강조해야 될는지 학습을 할 수 있는 개념을 의미한다. 물론 입출력 시퀀스가 자기 자신이 되는 셀프 어텐션 등 다양한 방식이 존재한다.
아래 그림은 어텐션이 인코더 디코더 사이에서 학습되는 방식을 도식화 한것이다. 입력 시퀀스 중에서 “방”이라는 단어가 “room”이라는 단어가 시퀀스에서 출현시 강조되는 것이며, 그러한 강조 정보가 입력 시퀀스에 적용되어서 디코더에 입력된다. 매 디코더 시퀀스마다 이러한 계산이 진행되며 수많은 문장이 학습되면서 인코더 디코더에 입력되는 단어들의 상호간의 컨텍스트가 학습된다.
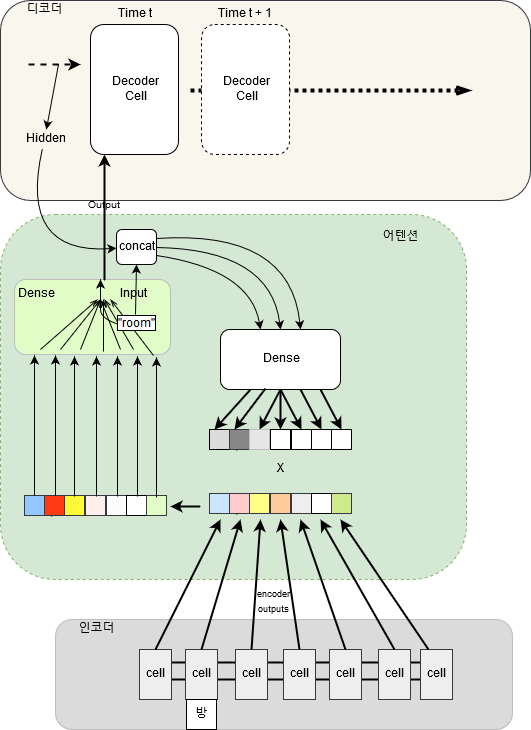
기계번역에서 어텐션은 다소 어려운 구현 방식중에 하나여서 좀더 일반적인 어텐션에 대해서 설명해보도록 하겠다(몇몇 잘못된 부분을 고쳤으며, 수식은 많은 부분 이곳[note]https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html[/note]을 참고했다).
아래와 같이 n길이를 가지는 입력 x 시퀀스와 m길이를 가지는 출력 y 시퀀스가 있다고 가정하자.
$x = [x_1, x_2, x_3, …, x_n] \\ y = [y_1, y_2, y_3, …, y_m]$
인코더의 Bi-GRU의 전방 히든상태 $\overrightarrow{h_i}$와 후방 히든상태 $\overleftarrow{h_i}$를 결합(concat)한 벡터가 존재한다고 하자.
$h_i=[\overrightarrow{h_i^T};\overleftarrow{h_i^T}], i = 1,…,n$
디코더에서의 출력 시퀀스 t의 히든상태는 $s_t = f(s_{t-1}, y_{t-1}, c_t)$로 구성되는데, 여기서 어텐션 결과인 컨텍스트 벡터 $c_t$를 구하기 위해 입력 시퀀스 모든 히든상태에 대한 정렬 스코어(alignment score) $\alpha$를 가중합한 형태로 사용하게 된다. 자세한 수식은 아래와 같다.
$\begin{aligned} c_t &= \sum_{i=1}^n \alpha_{t,i} \boldsymbol{h}_i & \small{\text{; 출력 } y_t\text{에 대한 컨텍스트 벡터}} \\ \alpha_{t,i} &= \text{align}(y_t, x_i) & \small{\text{; 얼마나 두 단어 }y_t\text{ 와 }x_i\text{ 가 잘 매칭하는지…}} \\ &= \frac{\text{score}(s_{t-1}, h_i)}{\sum_{i=1}^n \text{score}(s_{t-1}, h_{i}))} & \small{\text{; 정렬 스코어를 소프트맥스로 계산}}. \end{aligned}$
$\alpha_{t,i}$는 출력 $t$에 대한 입력 단어 $i$의 가중치라 볼 수 있고, 이를 가중치 벡터(weight vector)라고 한다. 여기서 score를 어떻게 정의하느냐에 따라 다양한 어텐션 종류가 생성되는데 초기 논문[note]https://arxiv.org/pdf/1409.0473.pdf[/note]에서는 아래와 같이 풀리 커넥티드 레이어(fully connected layer)인 Dense로 구현된다.
$\text{score}(s_{t-1}, h_i) = \mathbf{v}_a^\top \tanh(\mathbf{W}_a[s_{t-1}; h_i])$
$\mathbf{v}_a^\top$와 $\mathbf{W}_a$는 가중치 행렬로 학습의 대상이 된다.
어텐션이 학습에 큰 도움이 되는 것이 알려진 뒤에 출력, 입력 단어간의 내적으로만 스코어를 계산하는 방식과 함께 가중치 행렬 하나만을 이용한 단순한 방식 등 다양한 변종이 출현하게 된다.
$\text{score}(s_{t-1}, h_i) = s_{t-1}^\top h_i \\ \text{score}(s_{t-1}, h_i) = s_{t-1}^\top\mathbf{W}_a h_i$
또한 인코더 디코더 쌍이 아닌 하나의 입력을 흡사 인코더 디코더인것 처럼 학습해 입력 단어들간의 상관성을 학습하여 효과를 거둔 셀프 어텐션(Self-Attention)도 많이 활용된다[note]https://arxiv.org/pdf/1601.06733.pdf[/note]. 하나의 문장을 기준으로 셀프 어텐션을 적절하게 학습했다면 아래와 같은 효과를 볼 수 있고, 심지어 문장 안에서 멀리 떨어진 단어들의 관계까지 학습이 가능하다.

셀프 어텐션을 이용한 네이버 영화 리뷰 분류 모델
여기서는 과거 블로그 포스팅에서 이용한 네이버 영화 리뷰 분류 모형을 기반으로 셀프 어텐션을 활용해 보도록 하겠다. GluonNLP에서는 위에서 언급한 score 함수의 구현 방식에 따라 MLPAttentionCell, DotProductAttentionCell 이렇게 두가지 어텐션을 제공하고 있다. 사실 가장 범용적인 어텐션 방식이기 때문에 편하게 사용하기 좋은 알고리즘이다.
풀리 커넥티드 레이어 기반의 셀프어텐션과 Bi-GRU를 이용해 어텐션 API를 사용해 구현하면 아래와 같다.
>> class SentClassificationModelAtt(gluon.HybridBlock): >> def __init__(self, vocab_size, num_embed, seq_len, hidden_size, **kwargs): >> super(SentClassificationModelAtt, self).__init__(**kwargs) >> self.seq_len = seq_len >> self.hidden_size = hidden_size >> with self.name_scope(): >> self.embed = nn.Embedding(input_dim=vocab_size, output_dim=num_embed) >> self.drop = nn.Dropout(0.3) >> self.bigru = rnn.GRU(self.hidden_size,dropout=0.2, bidirectional=True) >> self.attention = nlp.model.MLPAttentionCell(30, dropout=0.2) >> self.dense = nn.Dense(2) >> def hybrid_forward(self, F ,inputs): >> em_out = self.drop(self.embed(inputs)) >> bigruout = self.bigru(em_out).transpose((1,0,2)) >> ctx_vector, weigth_vector = self.attention(bigruout, bigruout) >> outs = self.dense(ctx_vector) >> return(outs, weigth_vector)
self.attention의 인자로 Query와 Key가 들어가는데, 이 부분을 이전 레이어의 출력으로 동일하게 채워주면 셀프 어텐션으로 동작하게 된다.
self.attention에서 두개의 결과를 반환하는데, 첫번째 결과는 모델에서 예측을 하는데 직접 쓰이게 되는 컨텍스트 벡터($c_t$)이고 두번째 결과는 가중치 벡터($\alpha_{t,i}$)이다.
어텐션은 예측 성능을 높이는데 큰 도움을 주기도 하며, 가중치 벡터를 직접 출력하여 모델이 결과를 어떻게 도출하는지 확인할 수 있는 창구 역할도 수행하게 된다. self.attention에서 출력한 결과를 가지고 입력 문장(“가지고 있는 이야기에 비해 정말로 수준떨어지는 연출, 편집”, 부정리뷰)의 어텐션 정보를 시각화 해보면 아래와 같다.
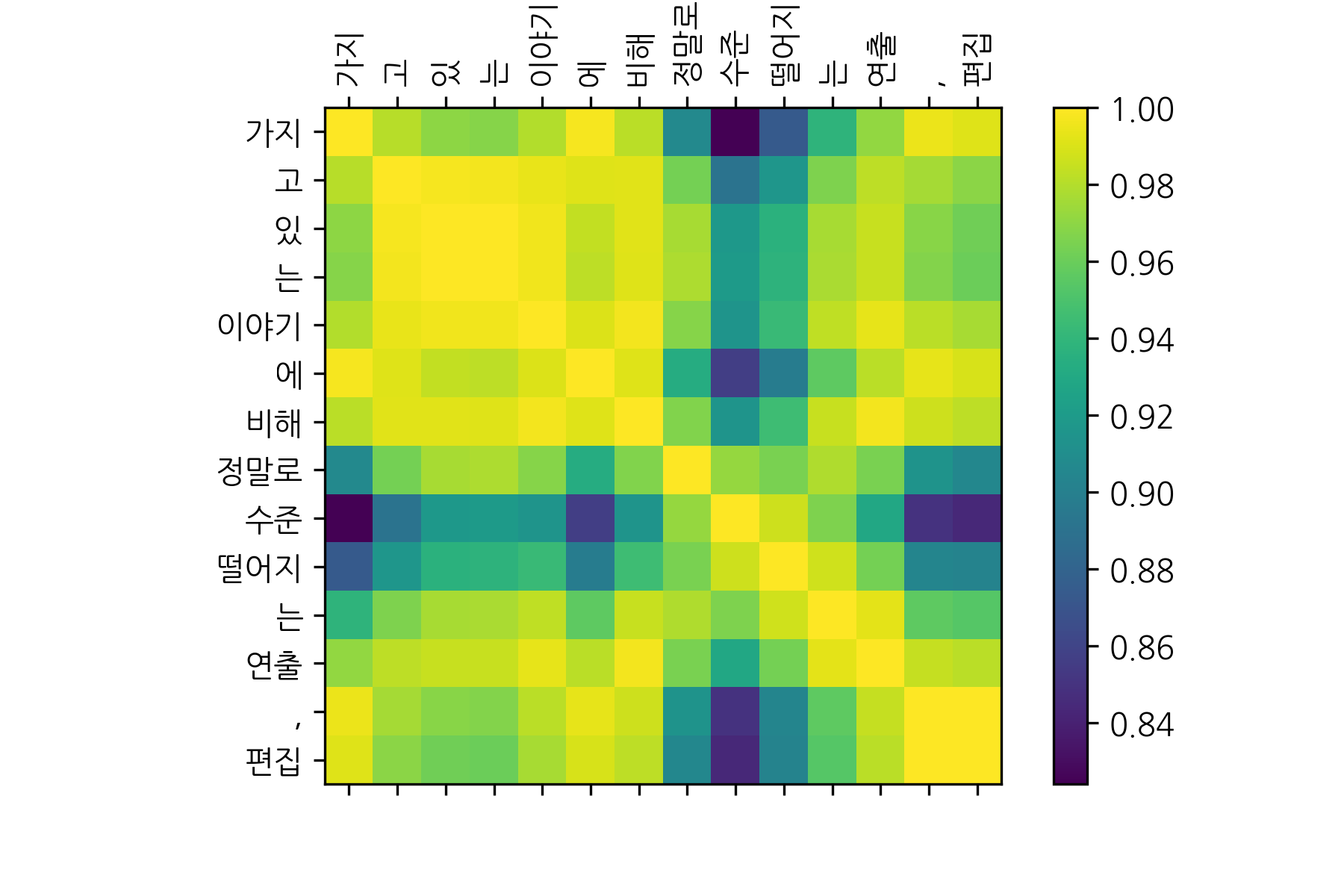
단순히 행렬을 시각화하고 각 시퀀스 단어를 축에 뿌려준 결과인데, “정말 수준 떨어지”와 같은 단어들이 상호간의 가중치를 서로 중요하게 발현하고 있음을 알 수 있다. 만일 모형이 과적합 되거나 제대로 학습되지 않았을 경우엔 이러한 가중치도 제대로 시각화 되기 어렵다.
결론
전체 소스코드를 이곳에 올려 놓았는데, 위 어텐션 활용 부분 뿐만 아니라 데이터 전처리 로직 전체를 GluonNLP를 이용해 고쳐봤다. 이전 블로그 포스팅 전처리 코드의 복잡도와 비교해보면 유사한 전처리를 했음해도 아주 간결하게 코드가 작성됨을 비교할 수 있을 것이다. 코드가 길어지면 재현성도 떨어지고, 실수도 늘게 마련이다. 따라서 이런 패키지는 고맙게 쓸 따름이다. 물론 기여할 수 있다면 더 보람될 것이다. 특히 NLP를 한다면 여기저기 신뢰성 없는 코드를 받아 쓰는 것 보다 좋은 결과를 내줄것이라 생각한다.