AI 에이전트 능력 예측 리포트 분석: 기술의 수명을 바라보며
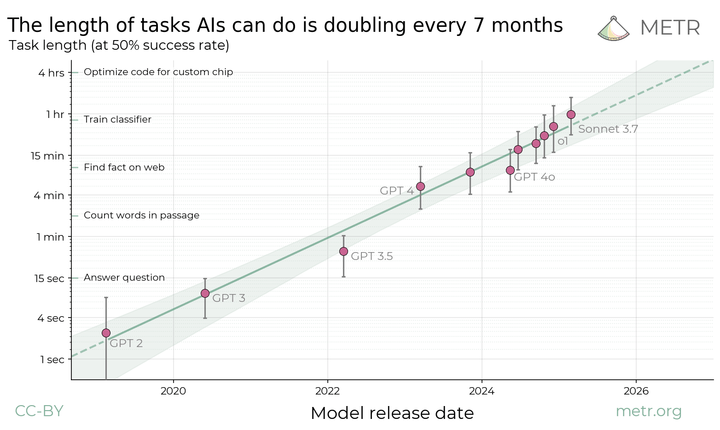
최근 METR에서 발표한 “Measuring AI Ability to Complete Long Tasks” 보고서는 AI 발전 추세에 대한 흥미로운 관점을 제시했습니다. 이 분석은 AI 기술을 활용하는 우리 모두에게 중요한 시사점을 던져주고 있어 오늘은 이 보고서의 핵심 내용과 제 생각을 공유하고자 합니다. METR 보고서의 핵심: 작업 길이를 통한 AI 능력 예측 METR 연구진은 AI 성능을 측정하는 새로운 접근법을 제시했습니다. […]
계속 읽기