
여행의 겹쳐 읽기
5월 한 달 동안 굴업도라는 섬을 두 번이나 방문을 했다. 아래는 굴업도 방문했던 소회를 글로 적어서 카페에 올린 글이다. 두 번째 글은 아래의 여행 유튜브 영상과 같이 보면 다른 사람의 관점에서 동일한 시점과 공간에서 섬을 어떻게 느꼈는지를 알 수 있을것이다. 보면 아시겠지만 두 유튜브에 내가 모두 출현한다. 그것도 이분들을 섬에서 우연히 만나고 이야기 하게 된 […]
계속 읽기
당신의 나의 뜨거운 감자!

PwC 2025 글로벌 AI 일자리 바로미터 심층 분석 최근 PwC에서 발표한 “두려움 없는 미래: 2025 글로벌 AI 일자리 바로미터(The Fearless Future: PwC’s 2025 Global AI Jobs Barometer)” 보고서가 흥미로운 데이터를 제시하며 AI와 일자리에 대한 새로운 관점을 던져주고 있습니다. 이 보고서는 전 세계 약 10억 건의 채용 공고와 수천 개 기업의 재무 보고서를 분석한 방대한 자료를 […]
계속 읽기
때로는 익숙한 모든 것으로부터 멀어지고 싶을 때가 있다. 분주한 도시의 소음, 반복되는 일상의 무게를 잠시 내려놓고, 낯선 풍경 속으로 발을 내딛는 순간, 우리는 비로소 새로운 숨을 쉬게 된다. 이번 여정은 그런 마음으로 떠난 굴업도, 그 섬이 품은 연평산과 덕물산에서의 하룻밤 이야기다. 새벽길을 달려 도착한 인천연안여객 터미널. 5월 황금 연휴와 주말을 맞이하여 예상치 못한 주차 대란에 […]
계속 읽기챗GPT가 세상에 나온 지 벌써 2년이 훌쩍 넘었습니다. 그동안 AI, 특히 생성형 AI는 우리 일상과 업무 방식에 엄청난 변화의 바람을 몰고 온게 사실입니다. 제가 몸담고 있는 소프트웨어 개발 분야가 아마도 그 첫 타깃이 되지 않을까 하는 생각이 점점 확신이 되고 있네요. AI 코딩 도구들이 등장하면서 “개발자 없이도 코딩하는 시대가 온다!”는 장밋빛 전망부터 “아직은 멀었다”는 신중론까지, […]
계속 읽기
AI 연구의 두 거장, ‘경험의 시대’ 선언 강화학습(RL) 분야의 세계적인 권위자 두 명이 AI의 미래에 대한 중요한 화두를 던졌습니다. 바로 리처드 서튼(Richard S. Sutton)과 데이비드 실버(David Silver)입니다. 이들은 수십 년간 기계가 ‘행동을 통해 배우도록’ 가르치는 강화학습 연구에 매진해왔습니다. 최근 컴퓨팅, 시뮬레이션, 딥러닝 기술의 발전과 RL 기반 제품의 성공에 힘입어, 이들은 AI 발전의 다음 단계를 “경험의 […]
계속 읽기지식노동의 변곡점 지난 몇 년간 AI는 단순 작업 자동화를 넘어 복잡한 지식노동 영역으로 빠르게 확장되고 있습니다. METR 연구소의 최신 연구에 따르면, AI가 완료할 수 있는 작업의 복잡성은 약 7개월마다 두 배로 증가하고 있다고 하죠. 이러한 지수적 성장은 2027년까지 우리가 일하는 방식을 근본적으로 변화시킬 것으로 예상합니다. 이 글에서는 몇가지 무리하지 않을 가정을 기반으로 2027년 AI 기반 […]
계속 읽기
익숙하지 않은 곳에서의 하룻밤. 낯선 공기, 낯선 침구, 낯선 소리들 속에 몸을 누이면, 오히려 마음은 오래된 기억처럼 느긋해진다. 그곳의 냄새를 맡고, 그곳의 음식을 입에 넣고 천천히 씹는다. 씹는 동안, 입안은 그 땅의 햇살과 바람, 사람의 손길을 천천히 떠올린다. 그것이 여행 아닐까. 장소를 옮긴다는 행위보다, 삶의 리듬을 조금 비틀고, 그 틈 사이로 들어오는 새로운 숨결을 받아들이는 […]
계속 읽기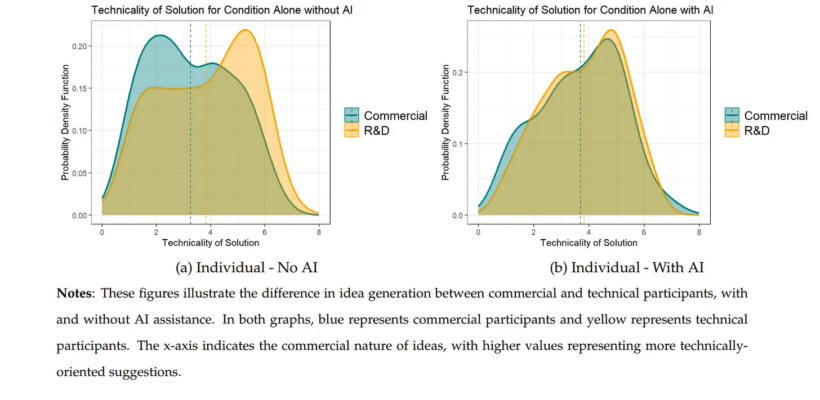
1. 연구 소개: 왜 P&G는 AI와 팀워크에 주목했는가 글로벌 소비재 거인 프록터 앤 갬블(P&G)은 최근 하버드 비즈니스 스쿨, 워튼스쿨, ESSEC 비즈니스 스쿨 등의 연구진과 협력하여 생성형 AI가 팀워크에 미치는 영향을 탐구하는 대규모 현장 실험을 진행했습니다. 디지털 데이터 디자인 연구소(Digital Data Design Institute at Harvard)에서 주도한 이 연구는 실제 업무 환경에서 AI의 영향력을 정확히 파악하기 위해 […]
계속 읽기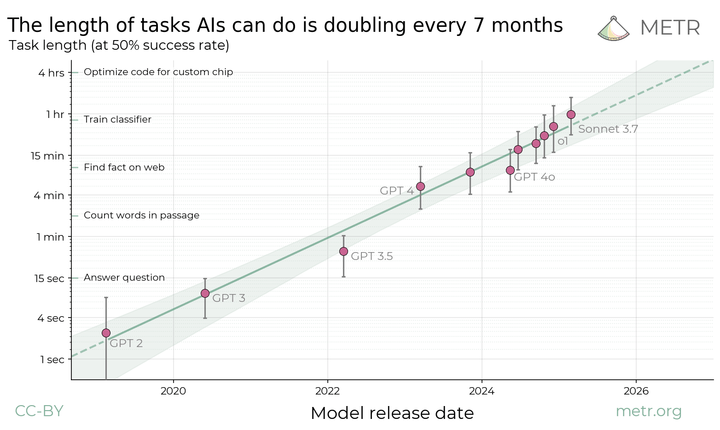
최근 METR에서 발표한 “Measuring AI Ability to Complete Long Tasks” 보고서는 AI 발전 추세에 대한 흥미로운 관점을 제시했습니다. 이 분석은 AI 기술을 활용하는 우리 모두에게 중요한 시사점을 던져주고 있어 오늘은 이 보고서의 핵심 내용과 제 생각을 공유하고자 합니다. METR 보고서의 핵심: 작업 길이를 통한 AI 능력 예측 METR 연구진은 AI 성능을 측정하는 새로운 접근법을 제시했습니다. […]
계속 읽기
“형님 태백 눈 엄청 왔데요” 라는 후배의 말을 미끼로 덥썩 물어 버리는데는 그리 오랜 시간이 걸리지 않았다. 무엇보다 겨울의 끝자락을 붙잡고 싶었다. 그래서 주말을 맞이하여 다시 길을 나섰다. 강원도로 향하는 길, 그것은 마치 사라져가는 계절을 마지막으로 어루만지는 행위처럼 느껴졌다. 나에게 있어 백패킹 계획이란 본래 먼 훗날의 일이 아니라, 수요일이나 목요일쯤 불현듯 결심을 하게 하는 그런 […]
계속 읽기