
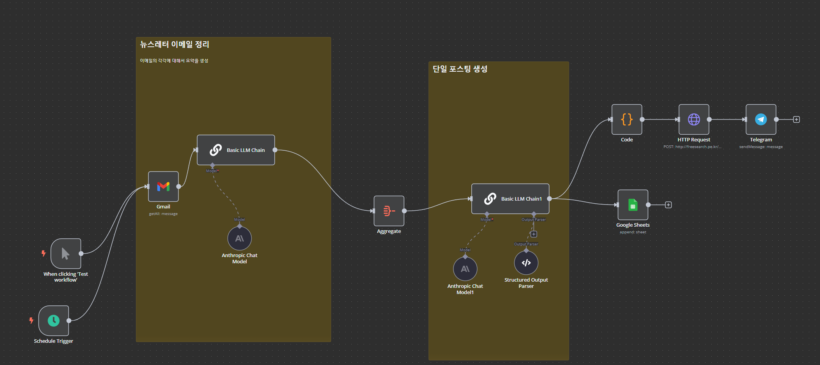
AI Agent의 현실과 이상 그리고 지금 해야 될 것
LLM 에이전트와 기술의 현재 위치 최근 들어 LLM(대규모 언어 모델) 기반 에이전트들의 성능과 가능성에 대한 논의가 활발히 이루어지고 있습니다. 이들은 웹 검색, 코드 작성, 프로그램 실행, 동료와의 소통 등 디지털 작업자와 유사한 방식으로 실제 업무를 수행할 수 있는 잠재력을 가진 도구로 주목받고 있습니다. 하지만 현재의 성과를 보면, 인간의 생산성을 완벽히 대체하기에는 아직 갈 길이 멀어 […]
계속 읽기
